Hadoop概述
- 高可靠
- 高扩展
- 高效
- 高容错
大数据
- 大量(Volume),多样(Variety),高速(Velocity),价值(Volue)
- 全体数据取代随机样本
- 混杂性取代精确性
- 相关关系取代因果关系
Hadoop的体系
Hadoop是对海量数据进行大规模分布式处理的开源软件框架
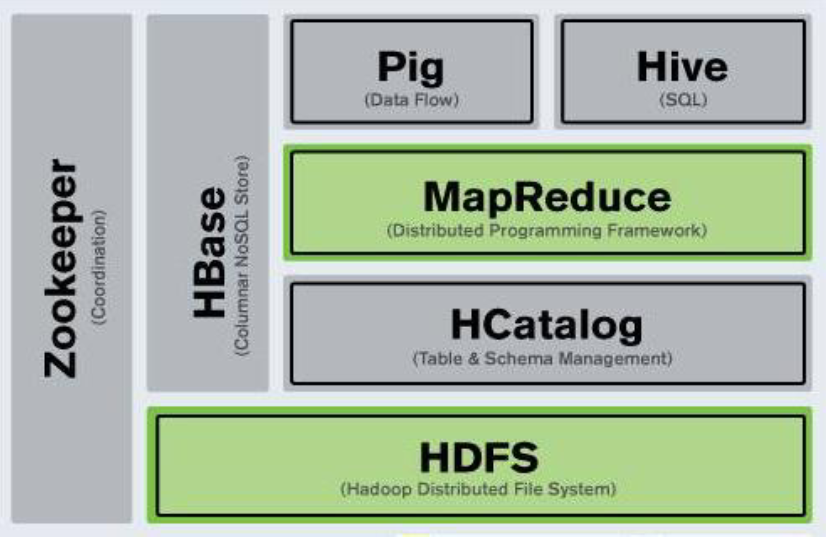
- HDFS—分布式文件系统;
- MapReduce—分布式处理模型;
- HBase—分布式数据库(非SQL)
- HCatalog—Hadoop内部数据整合工具,实现不同数据处理工具的数据类型相互转换机制;
- Pig—流式数据的数据处理语言及其运行环境;
- Hive—数据仓库管理工具,提供SQL查询功能;
- ZooKeeper—分布式协调器。
大数据与云计算关系
- 云计算就是把一大堆廉价机器组织起来,通过网络向用户提供海量资源的高性能可靠服务。
- 云计算为大数据处理提供了可能和途径
- 大数据为云计算具有的大规模与分布式计算能力提供了应用空间,利用云计算解决了传统数据管理系统无法解决的问题
Hadoop集群搭建
略😁
分布式文件系统HDFS
HDFS(Hadoop Distributed File System)是一个分布式的文件系统,适合一次写入多次读出的场景,不适合低延时访问,不适合小文件,不支持并发写入
HDFS架构
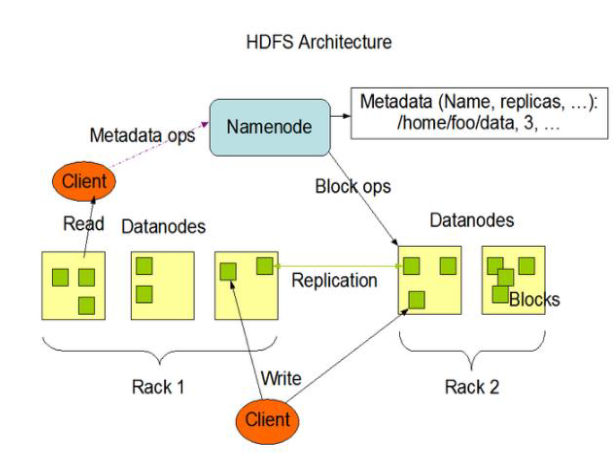
- NameNode:集群的Master
- 管理HDFS的命名空间
- 配置副本策略
- 管理块映射信息
- 处理客户端读写请求
- 负责监控各个DataNode的状态
- DataNode:集群的Slave
- 存储实际的数据块
- 处理数据块的读写请求
- 每次启动时扫描本地文件发送给NameNode
- Client:访问HDFS的客户端
- 文件切分,文件长传时将文件切分为一个个block
- 与NameNode进行交互,获取文件的位置信息
- 与DataNode进行交互,读写数据
- Secondary NameNode:辅助NameNode
- 定期合并FsImage和Edits文件,生成新的FsImage文件
- 在紧急情况下,可辅助恢复NameNode. 但是不是NameNode的热备份
HDFS对文件快大小的设置
- HDFS的默认块大小是128M
- HDFS的块大小设置是全局的,不支持单个文件设置
- 原因:
- 文件块越大,寻址时间越短,但磁盘传输时间越长;
- 文件块越小,寻址时间越长,但磁盘传输时间越短。
- 经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态
- HDFS中平均寻址时间大概为10ms;目前磁盘的传输速率普遍为100MB/s
- 所以最佳大小为100MB,所以设置最接近的128M
- 不固定,根据磁盘传输速率设置
HDFS操作
Shell操作
1 | # 上传 |
API操作
略
HDFS的读写流程
写流程

- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)
节点距离计算
- 在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据
- 两个节点到达最近的共同祖先的距离总和
副本策略
- 一个Block的第一个副本放在上传数据的DataNode上,
- 第二个副本放在与第一个副本在不同的机架上的另一个DataNode上,
- 第三个副本放在与第二个副本在相同的机架上的另一个DataNode上。
读流程
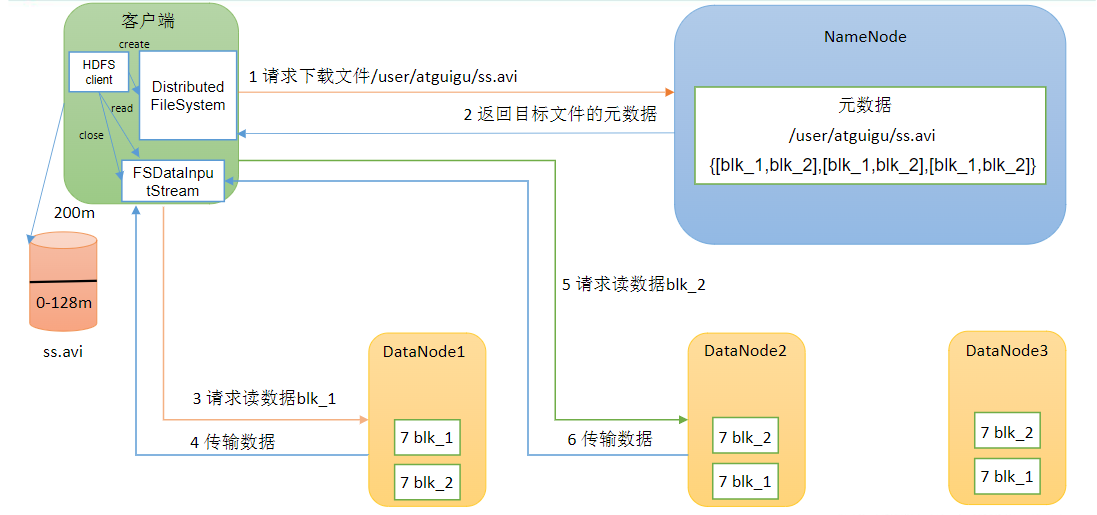
- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
HDFS高可用
NameNode和SecondaryNameNode
NameNode工作机制
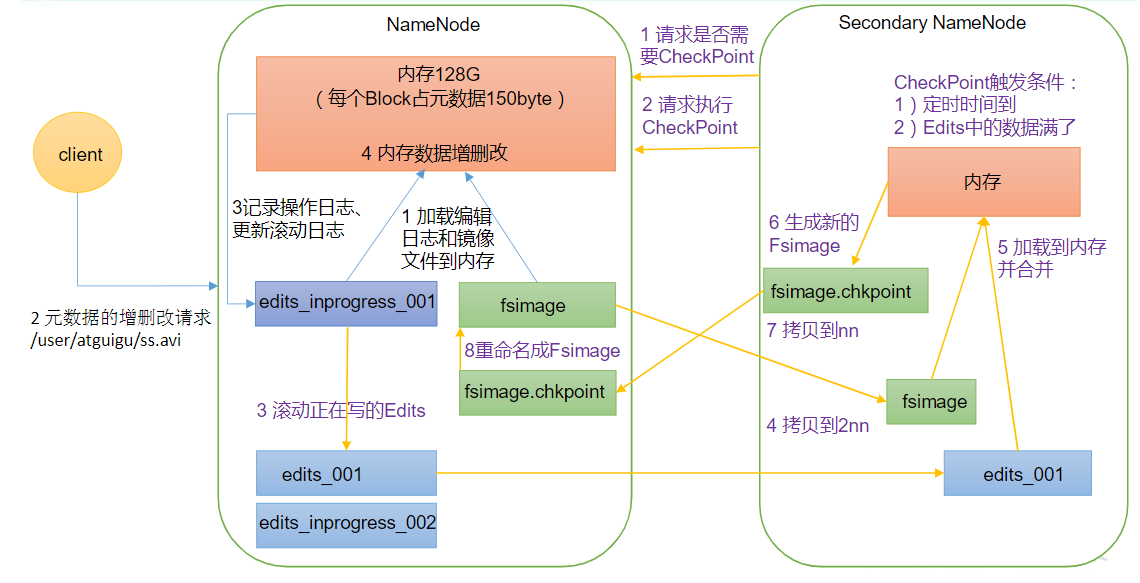
- NameNode将集群的文件镜像(FsImage)读到内存,当有新的操作来的时候,先将操作写到Edits文件中,然后再修改内存中文件镜像.
- NameNode每次启动时,加载FsImage文件和Edits文件,进行合并
NameNode长时间操作会导致Edits文件过大
- NameNode滚动正在写的Edits日志到一个新的文件edits_inprogress_002
- NameNode将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并
- 生成新的镜像文件fsimage.chkpoint,拷贝fsimage.chkpoint到NameNode
- 此时fsimage.chkpoint加上edits_inprogress_002就是最新的文件影像
问题:
- 如果Secondary NameNode正在合并的时候出问题了,则会导致期间NameNode的操作丢失
- 一般不会使用SecondaryNameNode,而是结合Zookeeper配置高可用
SecondaryNameNode合并时机
- 每隔一小时合并一次
- 每一分钟检测一下操作次数,如果到了100万,合并一次
DataNode工作机制(心跳检测)
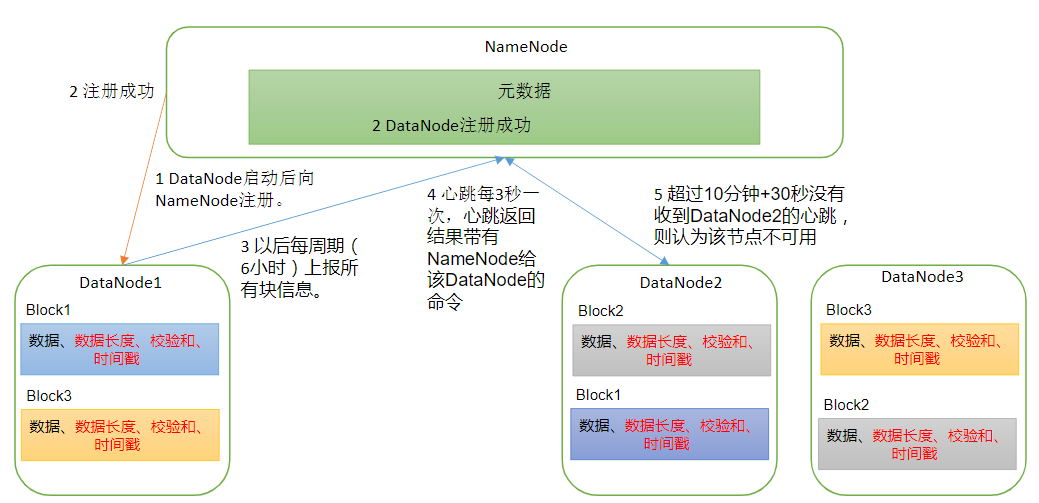
- DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信
- NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
- 默认超时时长10分钟+30秒
数据完整性 & 冗余备份 & 存储空间延时回收 & 客户端缓存 & 流水线式复制备份
数据完整性
- DataNode读取Block的时候会计算校验码,如果与创建的时候不一样,则Block孙华
- 读取其他DataNode的Block,使用crc32校验码
- DataNode在其文件创建后周期验证CheckSum
冗余备份
- NameNode定期检测各个数据块的备份数,并根据复制因子来增加或减少相应数据块的备份
- 文件备份数量= min(复制因子,DataNode的数量)
存储空间延时回收
- 删除文件在目录/trash内存放超过6小时,就会被系统彻底清除,并回收其存储空间
负载均衡
- 当某个DataNode上的空余磁盘空间下降到一定值,系统就把其部分数据块迁移到其它合适节点上去;
- 当出现对某个文件的访问频率超过一定值时,系统会创建该文件的新备份,对访问实施分流
客户端缓存
- 客户端写入文件的请求不是立即到达NameNode,而是先把写入数据存入本地缓存;
- 当本地缓存内数据达到一个数据块的大小(默认为128MB)时,客户端就请求NameNode分配一个文件数据块,并把本地缓存内的数据写入NameNode分配的数据块中
- 客户端的本地缓存可以极大地减少对网络的访问
流水线式复制备份
- 客户端写入数据块时,系统同时建立数据块的备份;
- 当一个DataNode接收数据进行写入操作时,随即把数据传给下一个节点写入,好似流水线一般
分布式计算模型MapReduce
MapReduce简介
MapReduce是一个分布式计算框架,MapReduce的设计思想是将计算过程分为两个阶段:Map阶段和Reduce阶段。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上
缺点:
- 不适合实时计算
- 不适合流式计算
MapReduce架构

InputFormat数据输入
切片与MapTask并行度决定机制
- 数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask
- 切片大小通常会与HDFS的块大小一致,但是也可以通过InputFormat来自定义切片大小
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
Job提交流程源码
1 | // 1. 等待任务完成 |
FileInputFormat切片源码
1 |
|
FileInputFormat切片机制
- (1)简单地按照文件的内容长度进行切片
- (2)切片大小,默认等于Block大小
- (3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
- 如果文件大小小于Block大小的1.1倍,默认也是不切片的
TextInputFormat切片机制
- TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。
- 键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型
CombineTextInputFormat切片机制
- 框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下
- 生成切片过程包括:虚拟存储过程和切片过程二部分
- 虚拟存储过程:
-
- 将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件平均分成2个虚拟存储块(防止出现太小切片)
-
- 例如:setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。
剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件平均切分成(2.01M和2.01M)两个文件。
- 例如:setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。
- 切片过程:
-
- 判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
-
- 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
-
- 测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M。这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M).最终会形成3个切片,大小分别为:(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
MapReduce工作机制
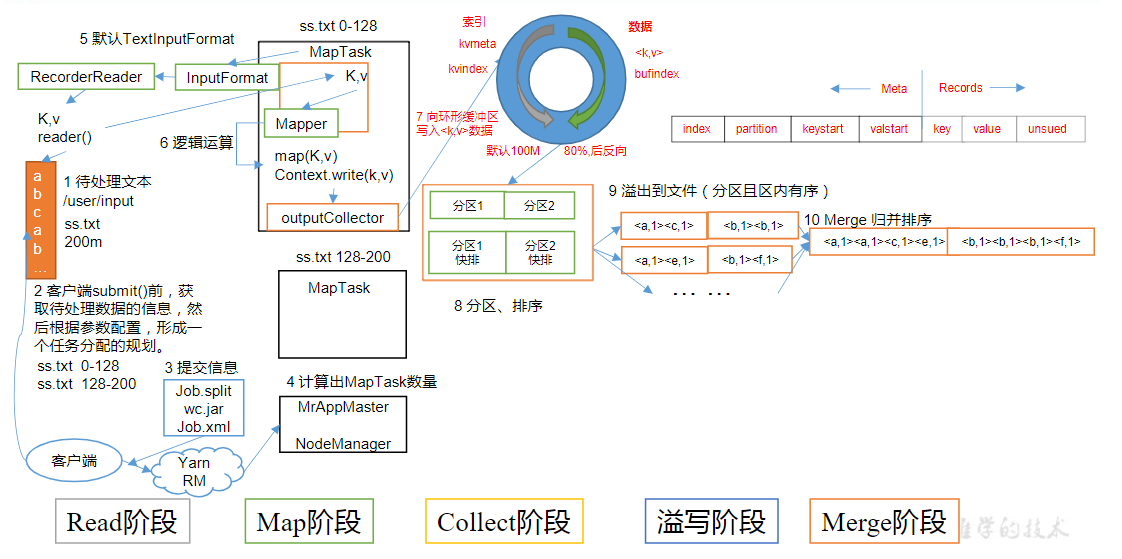
MaperTask工作机制
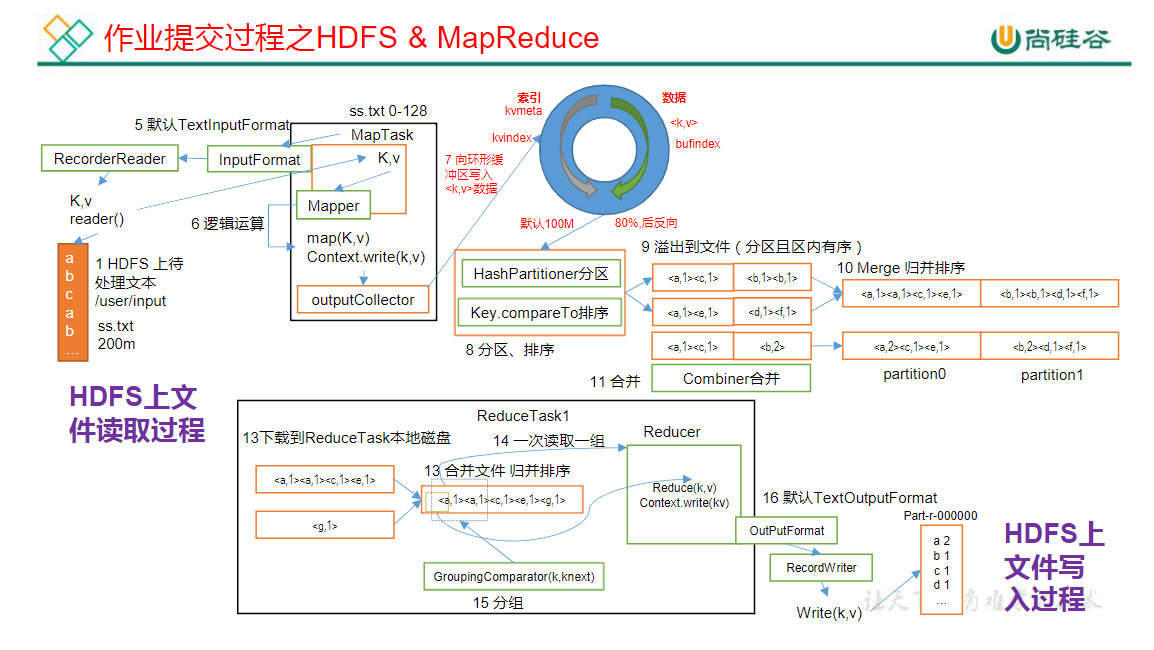
- Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个key/value
- Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value
- Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中
- Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作,溢写阶段详情:
- 步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序
- 步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作
- 步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中
- Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index
- 在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并mapreduce.task.io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件
- 让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销
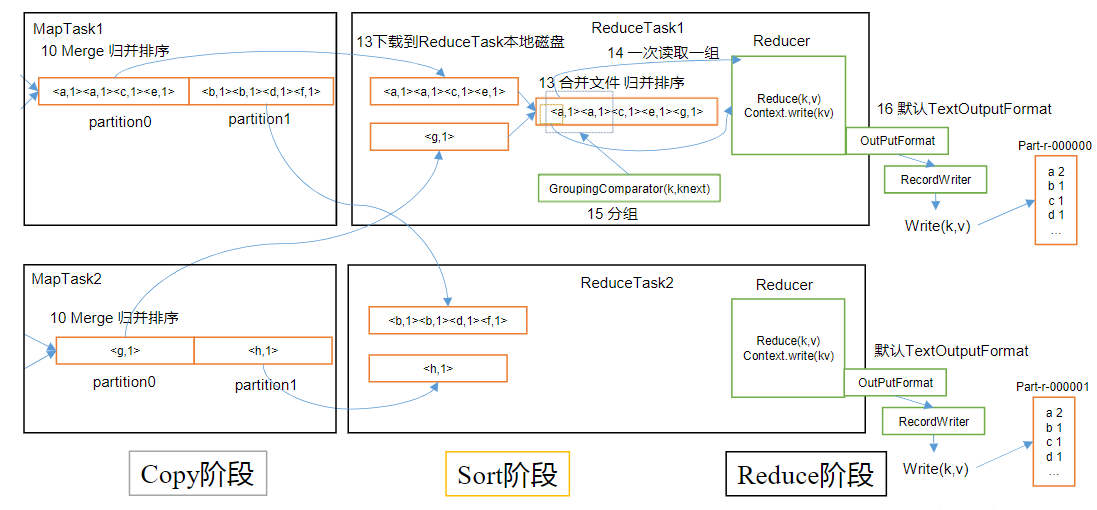
ReducerTask工作机制
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中
- Sort阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可
- Reduce阶段:reduce()函数将计算结果写到HDFS上
注意事项
- MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定
- ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置
- ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致
- ReduceTask默认值就是1,所以输出文件个数为一个
- 如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜
- ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask
- 如果分区数不是1,但是ReduceTask为1,不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行分区
Shuffle阶段
Shuffle机制
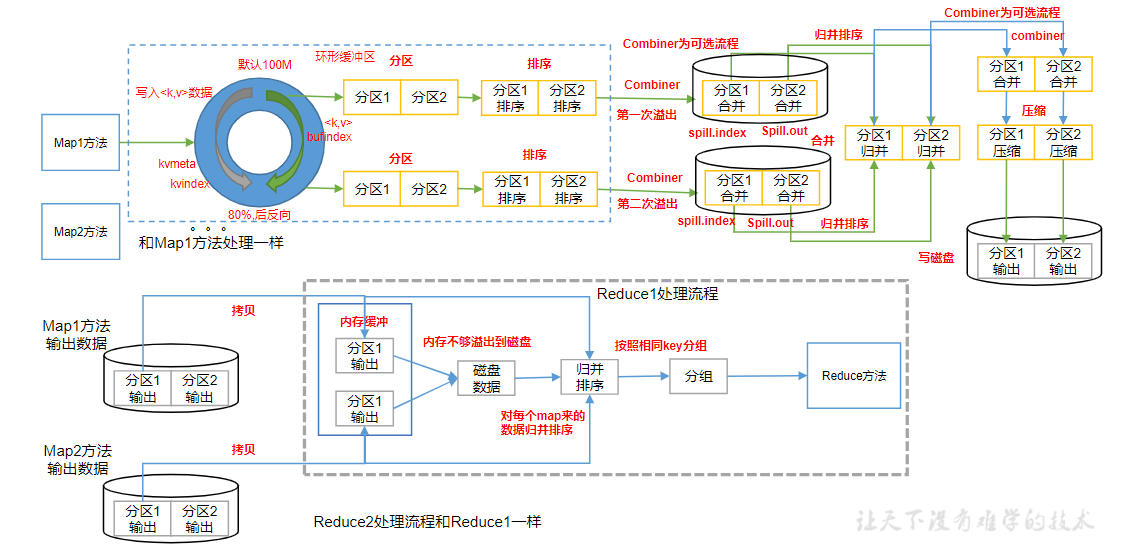
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
- Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
- 缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M
- 当缓冲区达到80%的时候,会启动一个后台线程将缓冲区中的数据写到磁盘上,同时继续接收新的数据
Parition分区
将MapTask输出的数据按照key进行分区,每个分区交给一个ReduceTask处理,默认分区是根据key的hashCode对ReduceTasks个数取模得到的
- (1)如果ReduceTask的数量>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx
- (2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
- (3)如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
- (4)分区号必须从零开始,逐一累加
WritableComparable排序
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序
- 对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序
- 对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序
- bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序
Combiner合并
- (1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
- (2)Combiner组件的父类就是Reducer。
- (3)Combiner和Reducer的区别在于运行的位置Combiner是在每一个MapTask所在的节点运行;
- (4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
- (5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来
OutputFormat数据输出
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。默认输出格式是TextOutputFormat
- 自定义一个LogOutputFormat类集成FileOutputFormat
- 重写getRecordWriter方法,返回一个自定义的LogRecordWriter
- 编写LogRecordWriter类, 具体改写RecordWriter的write方法,实现输出的逻辑
MapReduce编码
MapReduce编程规范
用户编写的程序分为三个部分:Mapper,Reducer,Driver
- Mapper阶段
- 用户自定义Mapper要集成的类
- Mapper的输入数据是KV对的形式(确定KV类型)
- Mapper的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式(确定KV类型)
- map()对每个KV调用一次
- Reducer阶段
- 用户自定义Reducer要集成的类
- Reducer的输入数据是KV对的形式(确定KV类型)
- Reducer的业务逻辑写在reduce()方法中
- Reducer的输出数据是KV对的形式(确定KV类型)
- reduce()对每一组相同的K调用一次
- Driver阶段
- 相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
Hadoop序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
对象一般只存在内存里,序列化后可以存储到磁盘,网络传输. Java序列化是一个重量级框架,一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制(Writable)
自定义bean对象实现序列化接口
- 实现Writable接口
- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造
- 重写序列化方法,重写反序列化方法(反序列化的顺序和序列化的顺序完全一致)
- 如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序
MapReduce编程
1)输入数据接口:InputFormat
(1)默认使用的实现类是:TextInputFormat
(2)TextInputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回。
(3)CombineTextInputFormat可以把多个小文件合并成一个切片处理,提高处理效率。
2)逻辑处理接口:Mapper
用户根据业务需求实现其中三个方法:map(), setup(), cleanup()
3)Partitioner分区
(1)有默认实现HashPartitioner,逻辑是根据key的哈希值和numReduces来返回一个分区号;key.hashCode()&Integer.MAXVALUE % numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4)Comparable排序
(1)当我们用自定义的对象作为key来输出时,就必须要实现WritableComparable接口,重写其中的compareTo()方法。
(2)部分排序:对最终输出的每一个文件进行内部排序。
(3)全排序:对所有数据进行排序,通常只有一个Reduce。
(4)二次排序:排序的条件有两个。
5)Combiner合并
Combiner合并可以提高程序执行效率,减少IO传输。但是使用时必须不能影响原有的业务处理结果。
6)逻辑处理接口:Reducer
用户根据业务需求实现其中三个方法:reduce(), setup(), cleanup()
7)输出数据接口:OutputFormat
(1)默认实现类是TextOutputFormat,功能逻辑是:将每一个KV对,向目标文本文件输出一行。
(2)用户还可以自定义OutputFormat。
Hadoop数据压缩
1)压缩的好处和坏处压缩的优点:
- 以减少磁盘IO、减少磁盘存储空间。
- 压缩的缺点:增加CPU开销。
2)压缩原则
- (1)运算密集型的Job,少用压缩
- (2)IO密集型的Job,多用压缩
3)压缩方式选择
- 压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片
4)压缩可以在MapReduce作用的任意阶段启用
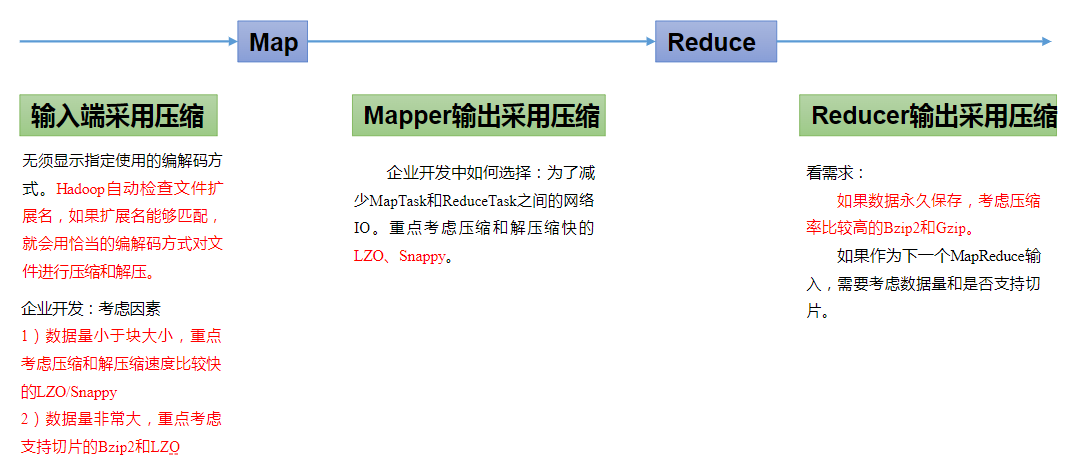
5)MR支持的压缩编码
| 压缩格式 | Hadoop自带 | 算法 | 文件扩展名 | 是否支持切片 | 原程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 是,直接使用 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
通用资源管理系统Yarn
Yarn简介
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
有任务推测执行功能
Yarn架构
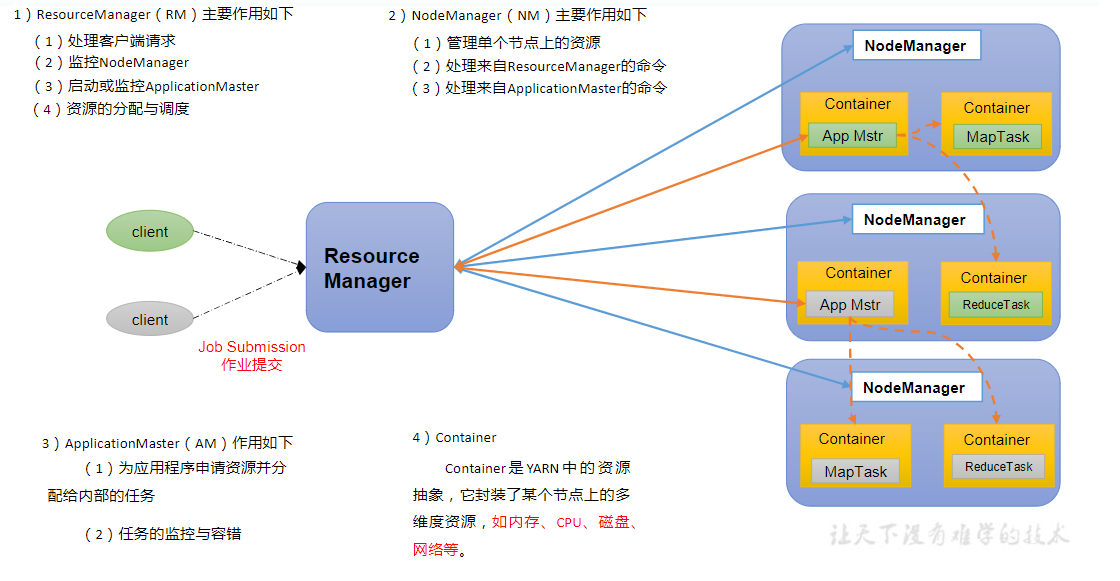
- ResourceManager:集群的Master
- 负责整个集群的资源分配和调度(调度策略)
- 监控NodeManager的运行状态
- 启动或监控ApplicationMaster的运行状态
- 处理客户端的请求
- NodeManager:集群的Slave
- 负责单个节点上的资源管理和任务管理
- 与ResourceManager通信,汇报节点资源使用情况
- 接收ResourceManager的命令,启动或停止Container
- 处理来自ApplicationMaster的请求
- ApplicationMaster:每个应用程序的Master
- 负责应用程序的管理和协调
- 与ResourceManager通信,申请资源,释放资源
- 与NodeManager通信,启动或停止Container
- 监控任务与容错
- Container:资源分配的基本单位
Yarn工作机制
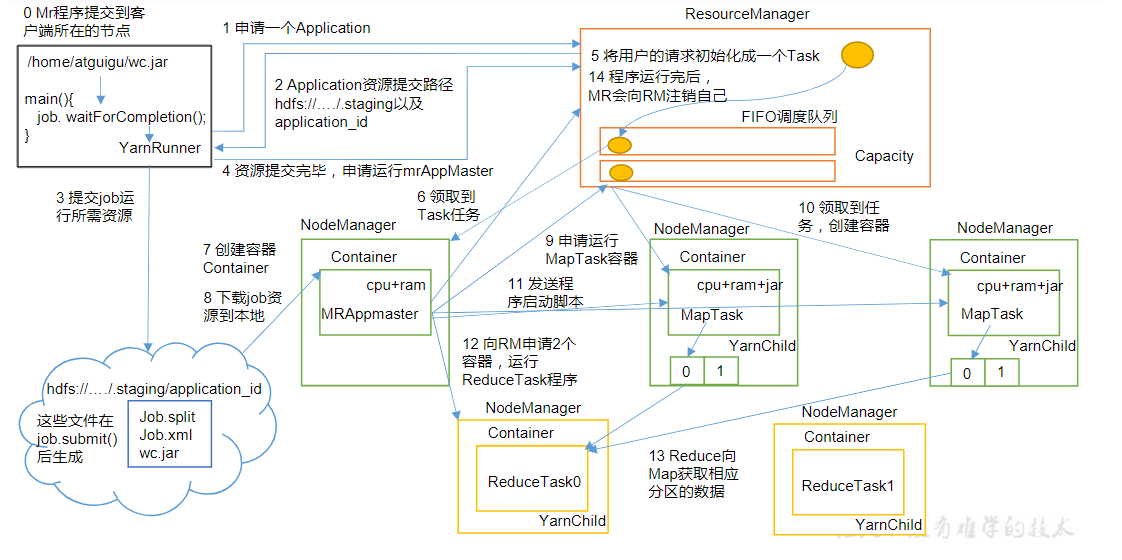
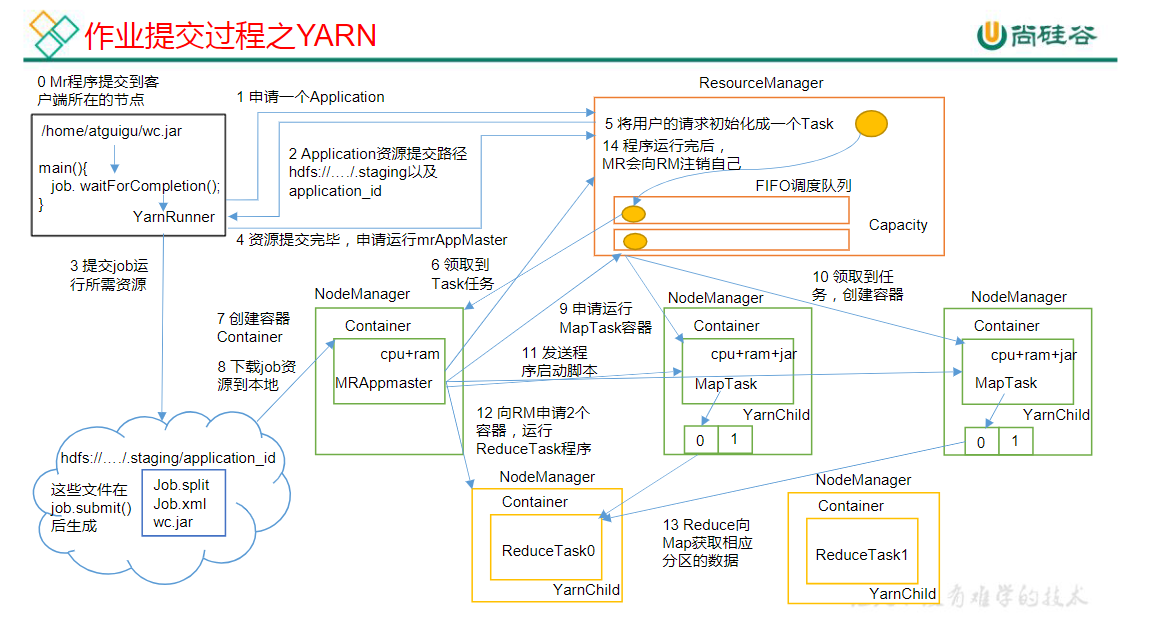
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
- 作业提交
- Client调用job.waitForCompletion()方法向集群提交作业
- Client向ResourceManager申请一个做业的id
- ResourceManager返回一个job资源的提交路径和id
- Client提交jar包,切片信息和配置文件到HDFS指定路径
- Client提交完资源后,向ResourceManager申请运行MRAppMaster
- 作业初始化
6. ResourceManager收到请求后,将该job添加到调度器中
7. 某个空闲的NodeManager领取到任务
8. 该NodeManager创建容器Container,并启动MRAppMaster
9. 从HDFS下载Client提交的资源到本地 - 任务分配
10. MRAppMaster向ResourceManager申请运行多个MapTask资源
11. ResourceManager将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器 - 任务执行
12. MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序
13. MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask
14. ReduceTask向MapTask获取相应分区的数据
15. 程序运行完毕后,MR会向RM申请注销自己 - 进度和状态更新
16. YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒向应用管理器请求进度更新, 展示给用户。 - 作业完成
17. 除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
Yarn的容错机制
ResourceManager的容错
- 借助Zookeeper实现高可用
ApplicationMaster的容错
- RM中的ASM负责监控AM的运行状态,一旦发现它运行失败或超时(在规定时间段内未使用为其分配的Container),就为其重新分配资源并启动它
- AM重新启动后如何恢复其内部的状态,则需由AM自己保证,比如MRAppMaster:
-
- 在作业运行过程中把状态信息动态记入HDFS中
-
- 在出现故障重启后,它就从HDFS中读取并恢复之前的状态,以减少重新计算带来的开销
NodeManager的容错
- 如果某个NM在规定的时间段内未向RM发送心跳消息(可能是网络方面的原因或NM自身的原因),RM则认为它已经宕机
- RM将该NM上所有正在运行的Container(任务)的状态置为失败,并分别通知它们所属作业的AM,由AM对这些Container中运行的任务作出处理
- AM替失败的任务向RM重新申请一个Container,并重新启动
- 如果AM自身使用的Container运行失败,则由RM中的ASM为其重新申请一个Container,并重启AM
Contrainer的容错
- 对于运行任务的Container,RM收回Container,并通知其申请者(AM),由它决定如何处理
- 对于运行AM的Container,RM收回Container,由RM中的ASM重新为它申请一个Container,并重启
☆Yarn的资源调度
对当前请求任务的节点进行检查
- 若该节点上的磁盘容量小于某阈值,则不再给该节点分配任务
- 若一个作业在该节点上运行失败的任务数量超过某阈值,则不再给该节点分配此作业的任务
Mapper任务调度
- 优先选择运行失败的任务,以让其尽快获得重新运行的机会;
- 其次按照数据本地性策略选择尚未运行的任务;
- 最后从正在运行的任务中推测是否有“拖后腿”任务,若有则为其启动备份任务
Reducer任务调度
- Reduce任务的数据来自多个节点,故没有数据本地性可言,即无须考虑本地性
Yarn做业调度主要有三种方式:FIFO,容量调度(默认),公平调度
FIFO调度
先到先得
容量调度
公平调度
Yarn命令
1 | # 查看所有的队列 |
Yarn的生产环境核心参数
1 | # 1.ResourceManager相关 |
分布式协调器Zookeeper
Zookerper简介
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目
是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookerper架构
ZooKeeper是一个由奇数(2n+1)台同构服务器组成的集群,它采用主-从结构
- 一台主服务器Leader,若干台从服务器Follower,只要有超过半数的服务器能够工作,ZooKeeper集群就能正常工作
- 集群内所有服务器均保持同步,都接受客户端的读写请求
- 如果ZooKeeper集群中的Leader出现了故障,那么Follower们就会通过一定的策略,选举出一个新的Leader;
Learder功能:
- 启动或重启时恢复数据
- 检测Follower的心跳
- 结束Foller发来的请求根据不同的类型做出处理,比如写
Follower功能:
- 接受Leader的消息,并完成工作
- 向Leader发送心跳
- 接受客户端的请求,如果为读请求,直接返回结果,如果为写请求,转发给Leader
Zookerper数据模型
Zookeeper维护一个类似于树状的文件系统
- 树状结构中有一个根节点,称为"/",其他节点建立在根节点上,每个节点称为ZNode
- 每个节点可以存储不超过1MB的数据,持久性的ZNode还可以在创建子节点
ZNode的类型:
- 持久性节点:一旦创建,除非主动删除,否则一直存在
- 持久性顺序节点:一旦创建,除非主动删除,否则一直存在,节点名后面会有一个递增的序号
- 临时节点:客户端断开连接后,该节点会被删除
- 临时顺序节点:客户端断开连接后,该节点会被删除,节点名后面会有一个递增的序号
ZNode组成:
- 访问控制列表(ACL):控制对ZNode的访问权限
- ZNode自身状态信息:创建者ID等
- ZNode数据:存储的数据
Zookeeper的一致性
会话(Session)机制
- 当客户端成功连接到ZooKeeper时,就与之建立了一个会话,客户端通过定时向ZooKeeper发送心跳消息来保持会话有效
- 如果ZooKeeper在规定时间段(默认为180秒)内未能收到某个客户端的心跳消息,则使其会话失效,即导致该客户端与ZooKeeper断开
- 如果因服务器负载过重、网络阻塞等导致客户端与ZooKeeper集群内某个服务器断开,客户端只要在规定时间段内与ZooKeeper集群内的任何一个服务器连接上,该会话仍然有效。
监视(Watcher)机制
- 客户端可以在某个Znode上设置一个Watcher(监视器),来监视该Znode的状态;
- Watcher一次性有效
- 一旦被设置了Watcher的Znode的状态发生变化,ZooKeeper服务端会将此事件通知设置Watcher的客户端,并根据事件类型触发回调客户端事先设置的处理逻辑
Zookeeper的自身一致性
myid:Zookeeper集群中每个服务器的唯一标识,myid文件中只包含一个数字,这个数字就是这个服务器的编号
ZXID:
- ZooKeeper为每个事务操作分配一个全局单调递增的事务编号(ZXID),每个ZXID对应于一次事务操作,它随事务一起被记入事务日志.
- ZXID是一个64位二进制数,其高32位为Leader周期的编号,称作epoch,新选出的Leader的epoch为其前任Leader的epoch值加1
- ZXID的低32位是一个单调递增的计数器,Leader在执行一个新的事务操作时,都会对该计数器作加1操作,其与epoch组合成此事务操作的ZXID
- 每当选举出一个新的Leader时,就从该Leader的事务日志内挑选出数值最大的事务编号ZXID,对其中的epoch值作加1操作,以此作为新Leader的周期编号,并将低32位置0,从而形成新的ZXID
原子广播ZAB (ZooKeeper Atomic Broadcast)
恢复模式:
- 系统启动或Leader发生故障时,ZAB进入恢复模式
- 立即进行一次Leader选举,选出一个新的Leader
- 让集群中至少有超过半数的Follower与Leader具有相同的系统状态,即实现数据同步
- ZAB退出恢复模式,进入广播模式
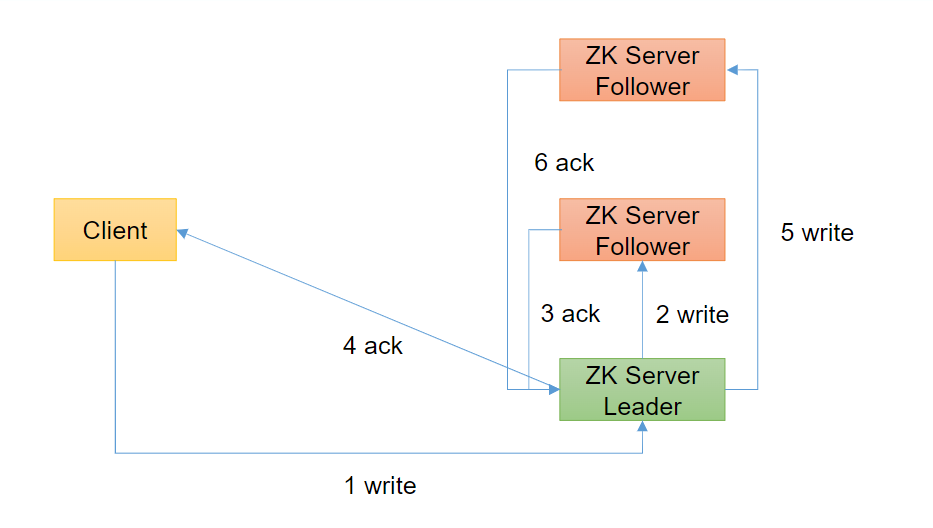
广播模式(写流程):
- Leader收到客户端发来的事务操作请求时,Leader通过ZAB的广播模式向集群内的所有Follower进行消息广播,即发送事务操作请求消息
- 各个Follower收到Leader广播(发送)的事务操作请求后,把将要作的事务操作及其ZXID记入各自的事务日志,然后向Leader回复ack(确认)消息
- 若Leader收不到超过半数的Follower回复的ack消息,则取消本次更新操作
- 若Leader收到超过半数的Follower回复的ack(确认)消息,则向Follower们进行消息广播—向它们发送commit(许可)消息
- Follower收到Leader的commit消息,就真正执行本次更新操作,即更新内存或Znode内的数据
- 整个ZAB的广播模式执行过程是一个整体,不能被打断,其结果只有成功或失败,不存在中间状态

Zookeeper的选举机制
选举的基本原则
- 选举开始时,ZooKeeper集群内各台服务器上的数据不一定会完全一致,在选出Leader之后,就要以该Leader为基准来同步其他服务器上的数据;
- 应该把集群内拥有最新数据的服务器选为Leader,故必须挑选其事务日志中具有最大ZXID的那台服务器作为Leader,因为该服务器进行了最新的事务操作,故其拥有的数据是最新的,以其作为基准来恢复和同步数据,则可以保证数据的完整性;
- 若具有最大ZXID的服务器不止一个,则选其中myid最大者为Leader
选举流程
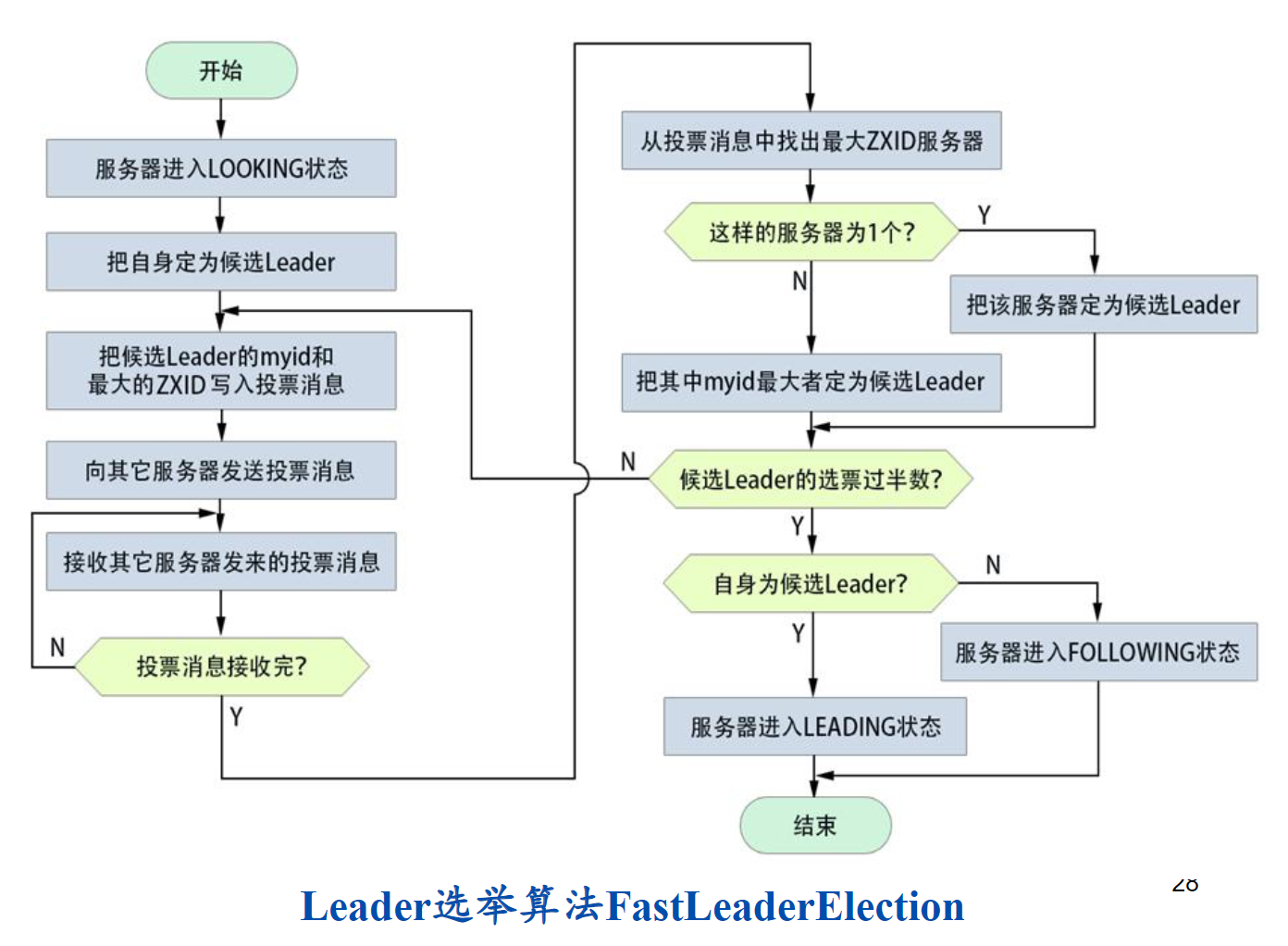
- 集群内各服务器均进入LOOKING状态,进行一轮选举投票,即各服务器均向其他服务器发送投票消息,消息的内容为自身的myid和自身最大的ZXID,也就是把自身定为候选Leader(争作Leader)
- 各服务器接收投票消息(包括自己的票),从中挑选出具有最大ZXID的服务器作为候选Leader ,若这样的服务器有多个,则挑选其中myid最大者
- 各服务器统计本轮投票中候选Leader的得票数
- 若未过半数,则把前一步挑选出的候选Leader的myid和ZXID记入投票消息,进行下一轮投票
- 如果候选Leader得票数过半,则判别候选Leader是否是自身,若是,则该服务器进入LEADING状态,否则该服务器进入FOLLOWING状态
### Zookeeper的操作
Shell操作
1 | # 查看节点 |
API操作
1 | // 创建监视点 |
分布式数据库HBase
简介
HBase是一种以HDFS为依据的分布式可扩展NoSQL列族数据库
NoSQL理论基础: CAP理论与BASE理论
传统关系数据库技术的核心特征:事务操作必须遵循ACID(原子性Atomicity、一致性Consistancy、隔离性Isolation、持久性Durability)原则,具有强事务、强一致性。
NoSQL数据库的特点:NoSQL方案弱化事务处理的ACID特性,一般不持支传统数据库的SQL查询语言
CAP理论:在设计和部署分布式应用时,存在三个核心的系统需求:
- C:Consistency(一致性)—在对数据进行更新和删除操作后,用户都能看到相同的数据视图。
- A:Availability(可用性)—可用性主要是指系统能够很好地为用户服务,不出现用户操作失败或者访问超时等用户体验不佳的情况(比如由强一致性带来的副作用)。
- P:Partition Tolerance(分区容错性)—分区容错性和可扩展性是紧密相关的,好的分区容错性要求一个分布式系统就像是一个运转正常的整体,当系统中有部分网络或节点发生故障时,仍然能够依靠系统中其余完好的部分来保证系统正常运作。
- CAP理论的核心:一个分布式系统不可能同时很好地满足一致性C,可用性A、分区容错性P这三个需求,最多只能同时较好地满足其中的两个需求。
OldSQL为了不降低可用性,通常对数据采用不分散存储的策略,使可扩展性(即分区容错性P)受到限制,可看作保证C、A,放弃P;
NoSQL为了获得可扩展性,又不降低可用性,在设计中就会弱化甚至去除事务的ACID要求,可看作保证A、P,放弃C。
BASE (BA,S,E) 理论:牺牲强一致性,获得可用性或可靠性,表现为以下三点:
- BA:Basically Availability(基本可用)
- S:Soft State(软状态)—允许系统中的数据存在中间状态,而这个中间状态不会影响系统的整体可用性。硬状态”是指严格遵循ACID原则的事务功能;
- E: Eventually Consistency(最终一致性)—系统中的数据经过一段时间后,最终会达到一致的状态。
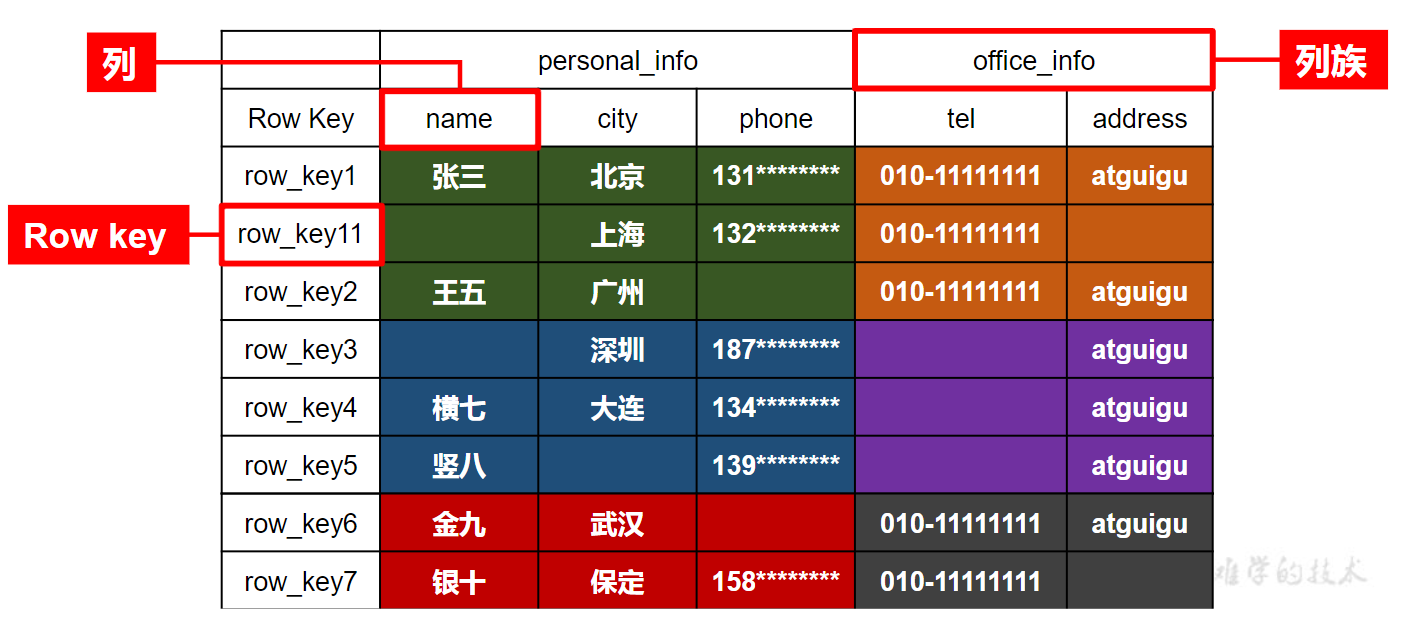
HBase逻辑结构
HBase的逻辑结构可以看作是一个二维的表格结构,行代表RowKey(唯一,按RowKey排序),列代表列族,其中列族下面可以有多个列限定符,每个列限定符下面存储一个值,这个值可以是多个版本的,每个版本都有一个时间戳,时间戳是一个64位的整数,代表了这个版本的时间,时间戳越大,版本越新
HBase物理结构
HBase的物理结构是基于HDFS的,每个表都会有一个对应的目录,目录下面有两个子目录,分别是data和wal,其中data目录存储了HFile文件,而wal目录存储了WAL文件(Write-Ahead-Log,预写日志).
HBase的RegionServer和HMaster不负责存储数据,只负责管理数据,而实际的数据存储在HDFS上
HBase数据模型
- Namespace: 命名空间,类似于关系数据库中的database概念.命名空间下可以有多个表,HBase自带两个命名空间,分别是default和hbase,hbase中存放的是HBase内置的表,其中meta表存放了所有表的元数据信息
- Table: 表,类似于关系数据库中的table概念,表中存放的是多行数据,每行数据都有一个唯一的RowKey,表中的数据是按照RowKey进行排序的
- Row: HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要
- Cell: 由{rowkey, columnFamily:columnQualifier, timestamp} 唯一确定的单元。Cell为空时,不会存储在HBase中.
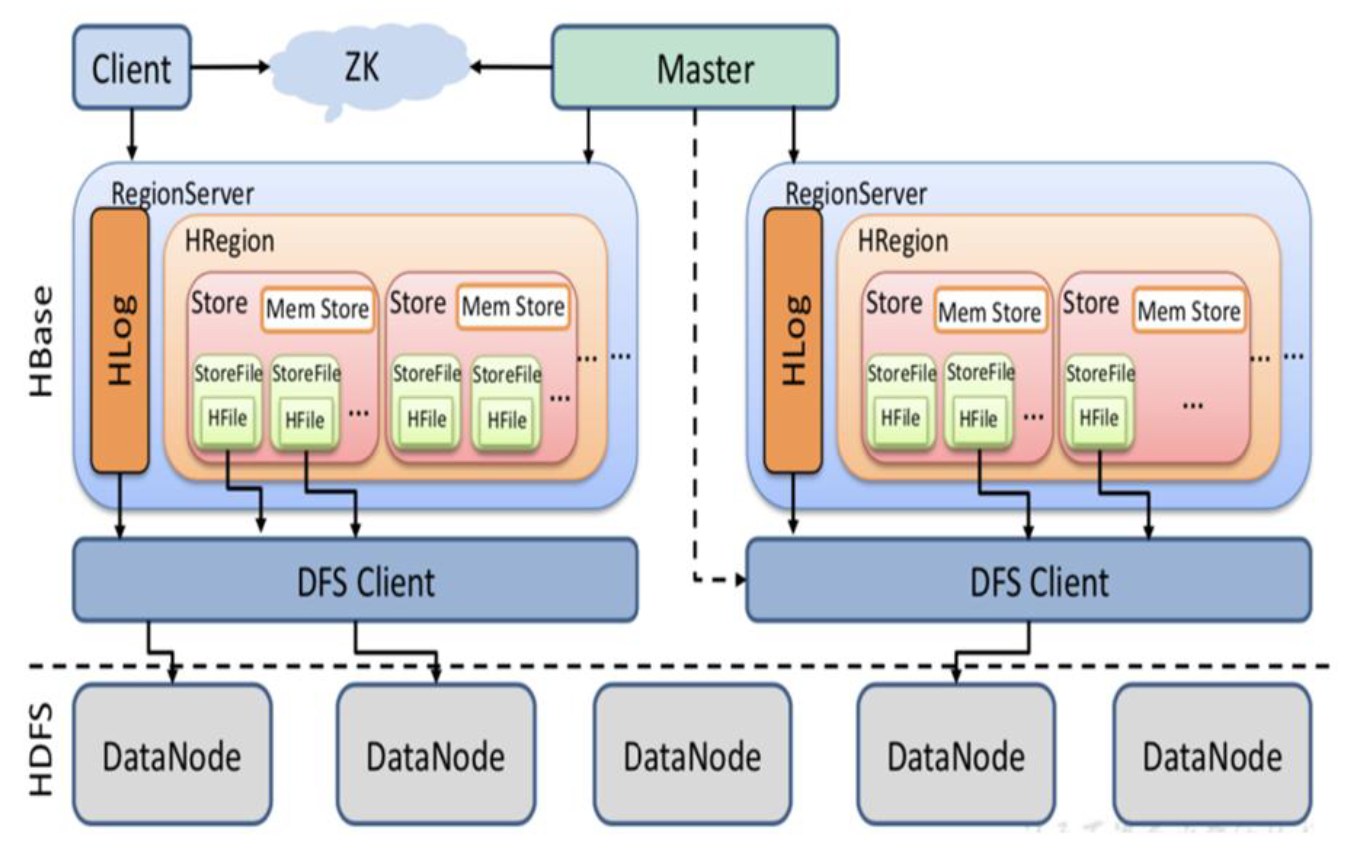
基本架构
-
Master服务器负责管理所有Region服务器和数据表(hbase:meta)
- 其本身不存储HBase中的数据;
- 接收用户对表格创建修改删除的命令并执行
- 监控region是否需要进行负载均衡,故障转移和region的拆分
-
Region服务器是HBase中最核心的部分:
- Region服务器是HBase的读写节点,它为用户提供对数据表数据的读写服务
- 一张数据表被划分成(横向划分)多个HRegion,这些HRegion被分布到Region服务器集群内进行管理
-
HRegion是一个HBase表横向切割的结果:
- 在HRegion中,每个列族又被分为一个Store.每个Store中存储了一个列族的数据,不包含空元素
- Store中包含一个MemStore,一个Block Cache和多个HFile,MemStore负责缓存写入的数据(有序,每次flush都回形成一个HFile),Block Cache负责缓存读取的数据,HFile是HBase中的数据存储文件
-
Zookeeper监视Region服务器和Master服务器的运行状态
- 各个Region服务器会在ZooKeeper的Z节点/server上建立临时性顺序节点,Master服务器在/server上设置Watcher,可以随时感知到各个Region服务器的运行状态;
- 当前的Active Master服务器在ZooKeeper上建立临时性Z节点/Master,各个Region服务器和Master集群内的其它服务器均在/Master上设置Watcher,它们可以随时感知到当前的Active Master服务器的工作(运行)状态;
HBase操作
Shell操作
基本操作
1 | # 创建命名空间 |
DDL操作
1 | # 创建表 |
DML操作
1 | # 插入数据 |
API操作
HBase的客户端连接由ConnectionFactory类来创建,用户使用完成之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对HBase的命令通过连接中的两个属性Admin(DDL)和Table(DML)来实现。
1 | // 创建连接 |
HBase在API操作时使用了装饰者(设计师)模式。因为shell命令的参数很多,所以在API中使用了装饰者模式,将参数封装成对象,然后通过对象的方法来实现shell命令的功能。
HBase一些原理
HBase架构
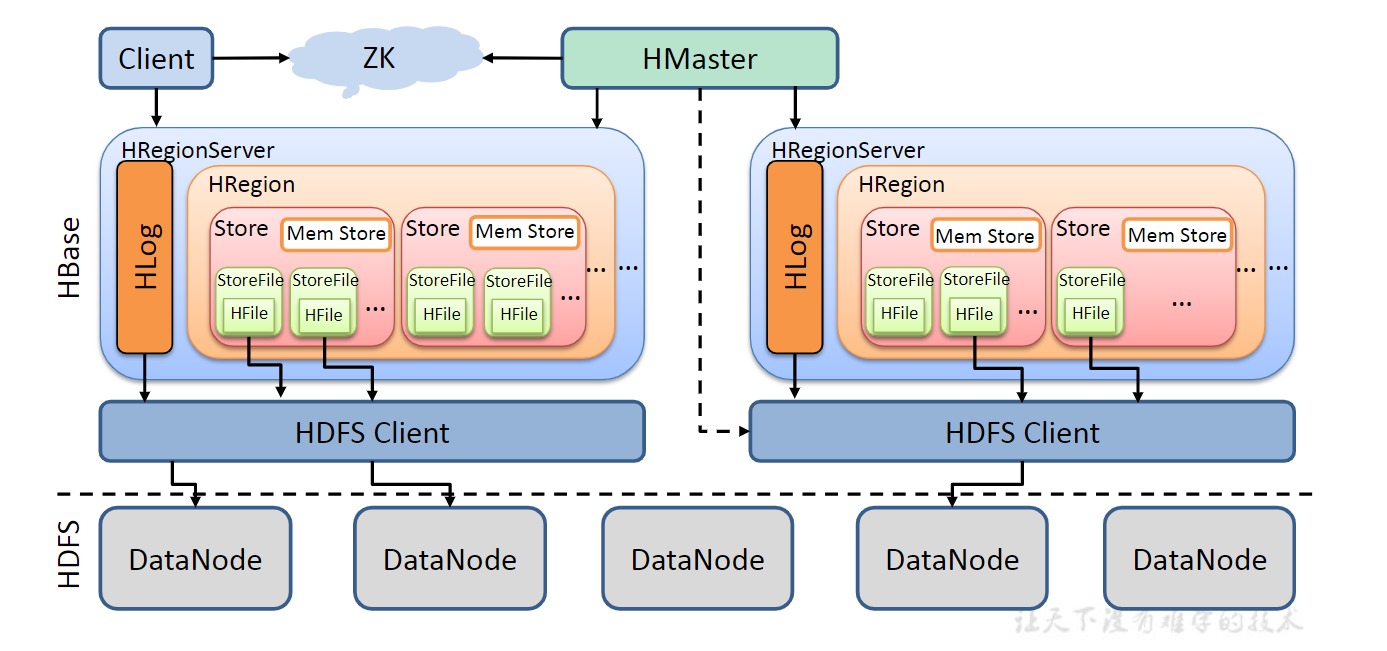
- hbase:meta 表中存储了 Hbase 集群中全部表的所有的Hregion 信息,在list命令中被过滤掉了
- StoreFile保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
- MemStore写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
- WAL由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
- Store
HBase的写流程
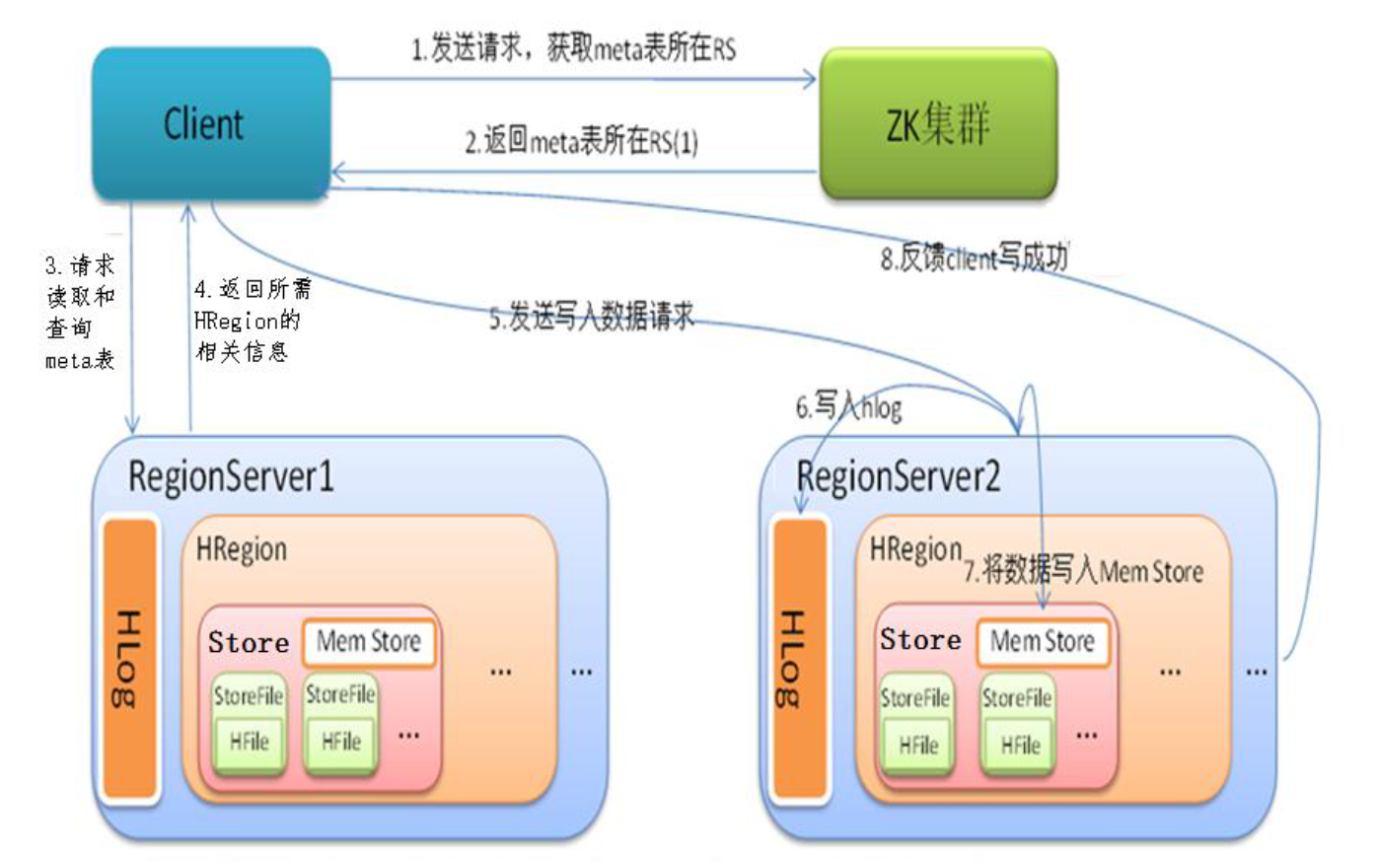
- Client先访问zookeeper,获取hbase:meta表位于哪个RegionServer。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标RegionServer进行通讯;
- 将数据顺序写入(追加)到WAL(HLog);
- 将数据写入对应的MemStore,数据会在MemStore进行排序;
- 向客户端发送ack;
- 等达到MemStore的刷写时机后,将数据刷写到HFile。
- 在步骤4,5,源码的步骤是先写入HLog,在写入MemStore,然后再同步HLog。如果HLog如果写入失败,就会事务回滚。
HBase的读流程
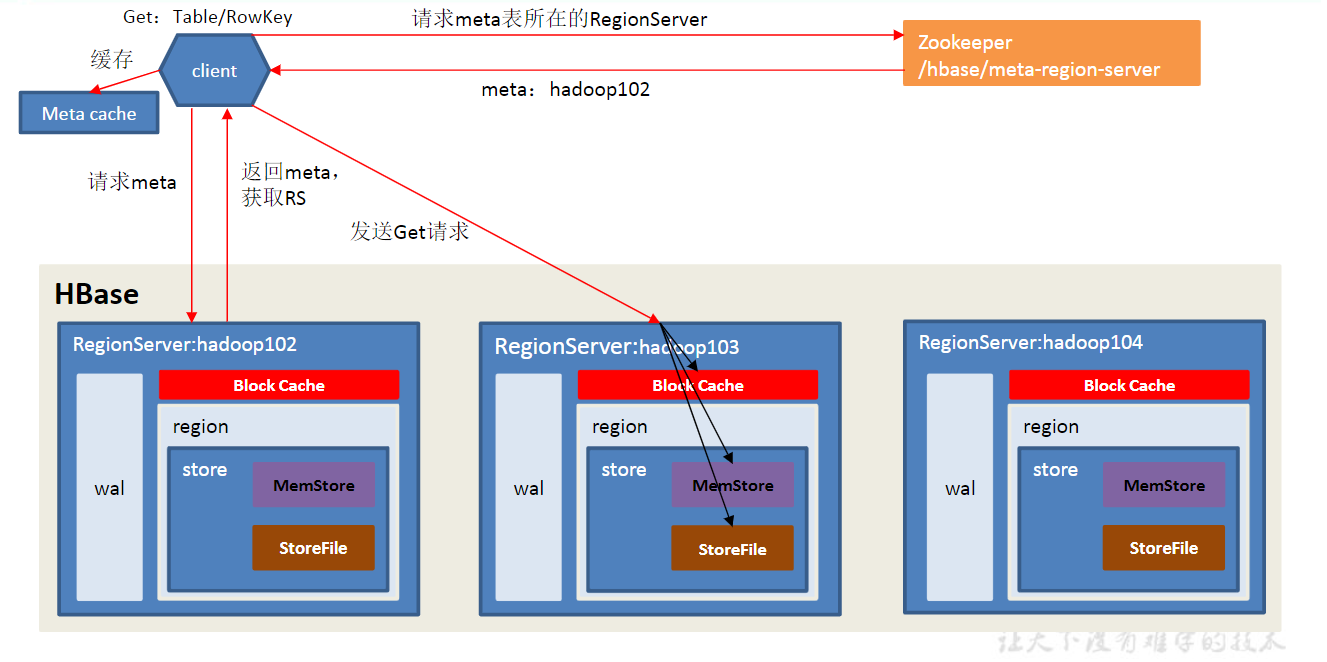
误区:HBase的读流程并不是只读BlockCache的数据,考虑这种情况:
第一次写数据的时候成功写入,并flush罗盘了
第二次写数据的时候写入了MemStore,但是此时把ts设置为了比第一次写的ts小,但是没有罗盘
如果只读BlockCache,那么第二次写的数据就会被读到,这样就会出现数据读取不是最新的情况。
- Client先访问zookeeper,获取hbase:meta表位于哪个RegionServer。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标RegionServer进行通讯;
- 分别在BlockCache(读缓存),MemStore和StoreFile(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(timestamp)或者不同的类型(Put/Delete)
- 将从文件中查询到的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到BlockCache。
- 将合并后的最终结果返回给客户端。
HBase的Flush操作
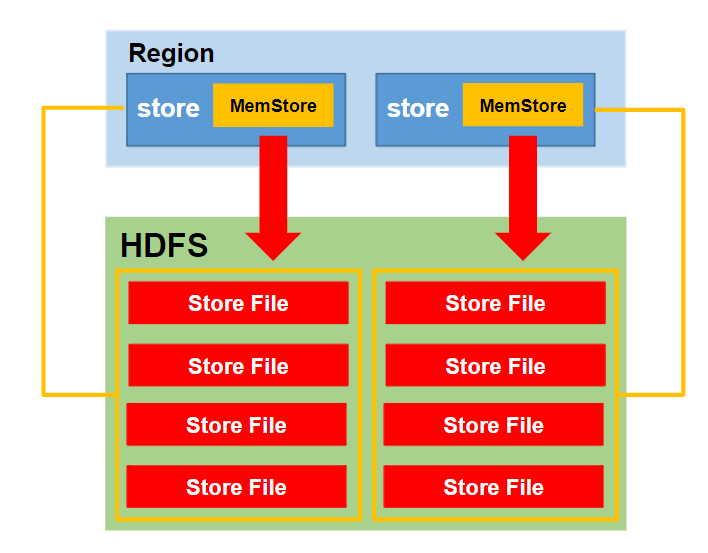
- Flush操作的基本单位是HRegion,即对HRegion的所有MemStore均进行Flush操作,并各自形成单独的StoreFile
- MemStore中的数据达到阈值(128M)后,其所在region的所有memstore都会刷写。
- 到达自动刷写的时间(默认1小时),最后一次刷写的时间到当前时间间隔超过了自动刷写的时间间隔。
- HRegion的所有MemStore中的数据总量到达阈值(JVM heap的40%)后,也会触发Flush操作。
- 当阈值到低位线(总阈值的95%,JVM heap的38%)时,region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
- 当阈值到高位线时,region会同时阻止继续往所有的memstore写数据。
HBase的Compaction操作
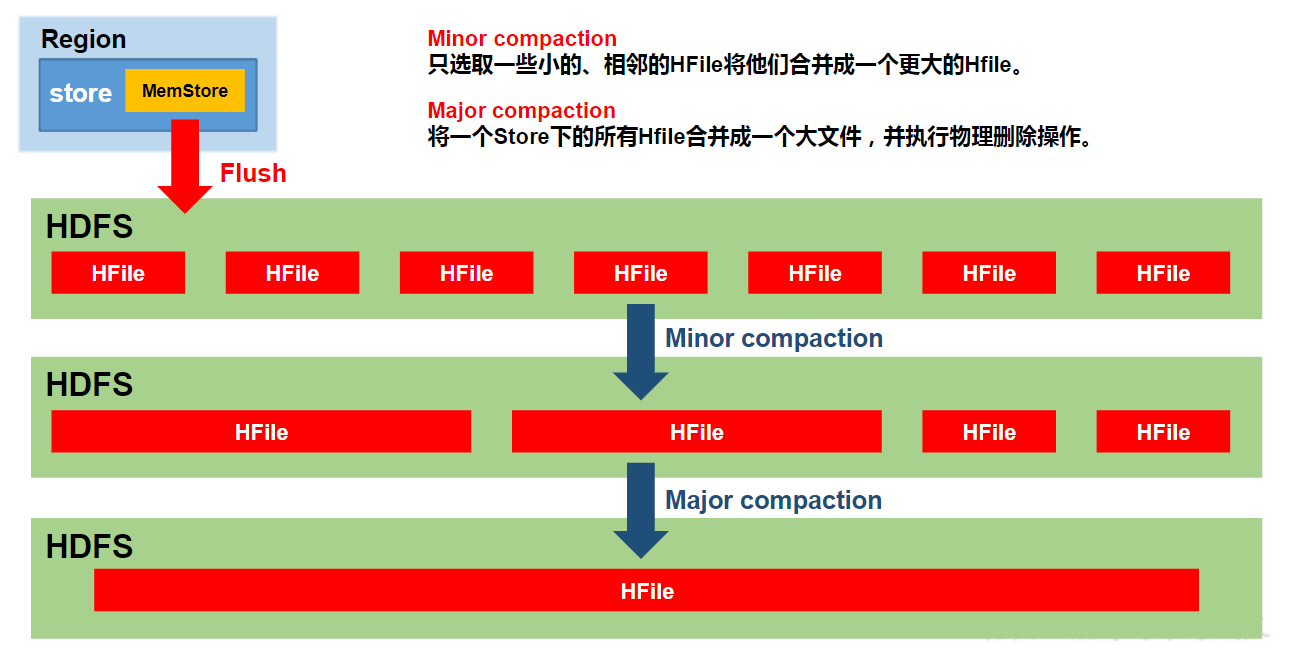
Compaction合并的原因:
StoreFile是只读文件,其内容不能被更新(增加、修改、删除),以此提升表数据的安全性
如果要更新StoreFile内的表数据,则必须以新增StoreFile的形式进行,把欲更新的数据(包含属性或版本号)写入新增的StoreFile中
(HBase不停的刷写,导致存储目录中有过多的数据文件,文件太多会导致维护困难、降低数据查询性能和效率。对一堆的文件进行I/O操作,耗时太多。所以HBase定期会对这些琐碎的文件进行整理,即合并Compaction。)
Compaction合并的步骤:
分为三步:排序文件、合并文件、代替原文件服务。
HBase首先从待合并的文件中读出HFile中的key-value,再按照由小到大的顺序写入一个新文件(storeFile)中。这个新文件将代替所有之前的文件,对外提供服务。
Compaction操作分为两种:
- Minor Compaction:只合并相邻的(3个)小文件,不会合并所有的文件,不会清理过期和删除的数据。
- major Compaction:合并所有的文件,产生一个新的文件。
Compaction大合并时,清空以下数据:
- 标记为删除的数据。
- 当我们删除数据时,HBase并没有把这些数据立即删除,而是将这些数据打了一个个标记,称为“墓碑”标记。在HBase合并时,会将这些带有墓碑标记的数据删除。
- TTL过期数据
- TTL(time to live)指数据包在网络中的时间。如果列族中设置了TTL过期时间,则在合并的过程中,发现过期的数据将被删除。
- 版本合并
- 若版本号超过了列族中预先设定的版本号,则将最早的一条数据删除。
Compaction合并的触发条件:
- 内存中的数据flush刷写到硬盘上以后,会对当前Store中的文件进行判断,当数量达到阈值,则会触发Compaction。
- Compaction Checker线程定期检查是否触发Compaction,Checker会优先检查文件数量是否大于阈值,再判断是否满足major Compaction的条件的时间范围内(7天),如果满足,则触发一次大合并Major Compaction。
- 手动合并
HBase的Split操作
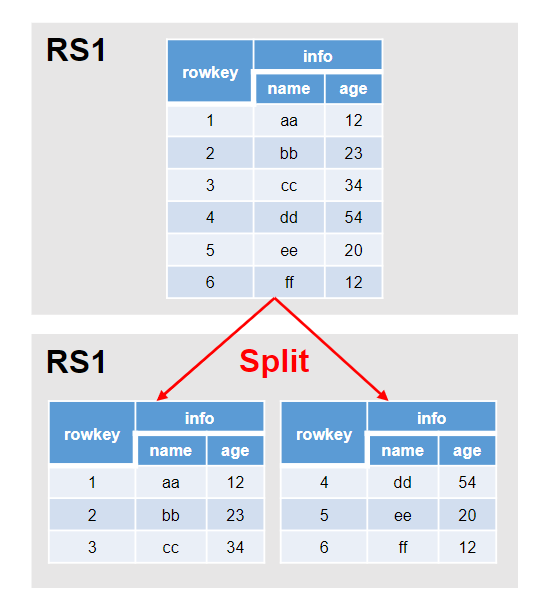
Split原因:
随着HRegion内的数据被持续追加,StoreFile文件的数量和长度会不断增大,由此引起Store的不断增大,从而导致HRegion的长度持续增大;
Split条件:
当1个region中的某个Store下所有StoreFile的总大小超过Min(R^2 * “hbase.hregion.memstore.flush.size”," hbase.hregion.max.filesize ") 就会拆分,其中R为当前RegionServer中属于该table的region个数
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,
因此取较小的值10GB 后面每次split的size都是10GB了。
Split过程:
Region的拆分是由HRegionServer完成的,在操作之前需要通过ZK汇报master,修改对应的Meta表信息添加两列info:splitA和info:splitB信息。之后需要操作HDFS上面对应的文件,按照拆分后的Region范围进行标记区分,实际操作为创建文件引用,不会挪动数据。刚完成拆分的时候,两个Region都由原先的RegionServer管理。之后汇报给Master,由Master将修改后的信息写入到Meta表中。等待下一次触发负载均衡机制,才会修改Region的管理服务者,而数据要等到下一次压缩时,才会实际进行移动。
离线数据仓库Hive
Hive简介
Hive是一个基于Hadoop的数据仓库工具(一个Hadoop的客户端),可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。
- Hive中每张表的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
- 执行程序运行在Yarn上
Hive的架构
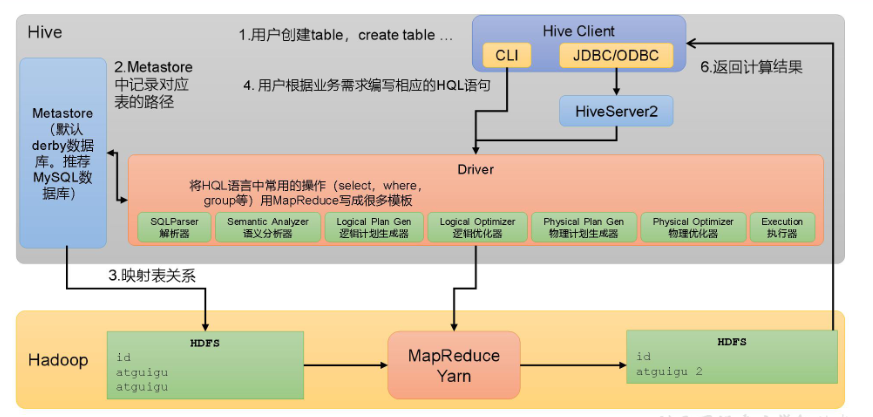
-
Hive Client
- Hive CLI:Hive提供的命令行接口(只能在安装了Hive的机器上使用)
- 远程连接的话需要使用JDBC或者ODBC客户端,连接到HiveServer2
-
Metastore:提供元数据的访问接口
- 元数据是指:用户创建的数据库,表的一些信息(在HDFS中的路径,字段信息等)
- 只负责提供元数据的访问接口,不负责存储元数据
- 元数据通常保存在关系型数据库中,默认是Derby,推荐是MySQL(derby数据库的特点是同一时间只允许一个客户端访问。如果多个Hive客户端同时访问,就会报错。)
-
HiveServer2
- 提供JDBC或者ODBC的访问接口
- 提供用户认证功能
-
Driver:需要用到元数据信息
- 解析器:将SQL字符串解析成抽象语法树
- 语义分析:将抽象语法树转换成QueryBlock
- 逻辑计划生成器:将语法树生成逻辑计划
- 逻辑优化器:对逻辑计划进行优化
- 物理计划生成器:将逻辑计划生成物理计划
- 物理优化器:对物理计划进行优化
- 执行器:执行物理计划得到结果返回客户端
元数据库配置
- 安装好MySQL,并新建数据库
create database metastore - 将MySQL的JDBC驱动拷贝到Hive的lib目录下
- conf目录下新建hive-site.xml文件,添加mysql配置项
1 | <configuration> |
- 初始化源数据库
bin/schematool -dbType mysql -initSchema -verbose - 使用Hive新建表,查看MySQL中的metastore数据库,可以看到Hive的元数据信息
1 | -- Hive中创建表 |
Hiveserver2服务配置
- Hiveserver2说明
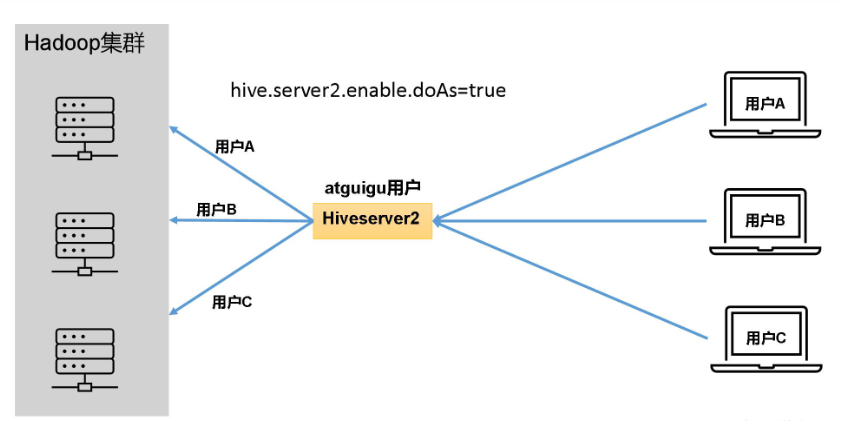
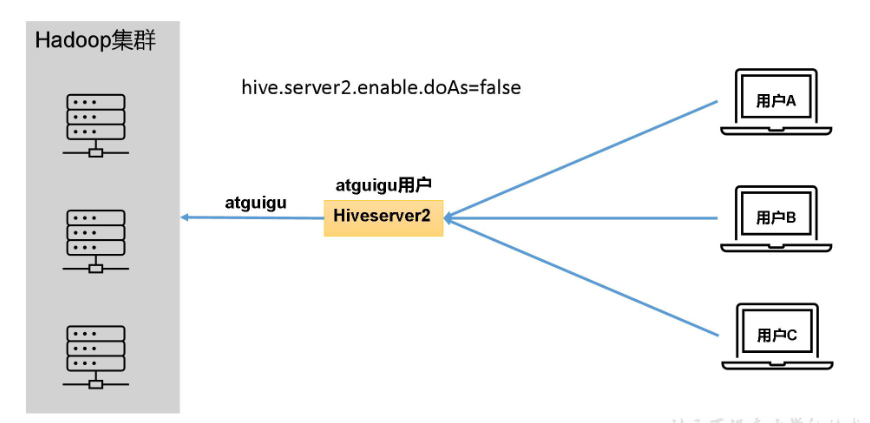
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。
若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,
不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。
推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
- Hiveserver2配置
1 | <!-- # Hadoop |
启动
bin/hive--servicehiveserver2
- Hiveserver2使用
- Hive提供的Beeline命令行客户端
bin/beeline,然后!connect jdbc:hive2://hadoop102:10000,输入用户名密码 - Datagrip图形化客户端
- Hive提供的Beeline命令行客户端
MetaStore服务配置
- MetaStore的服务模式
Hive的metastore服务的作用是为HiveCLI或者Hiveserver2提供元数据访问接口
metastore有两种运行模式,分别为嵌入式模式和独立服务模式
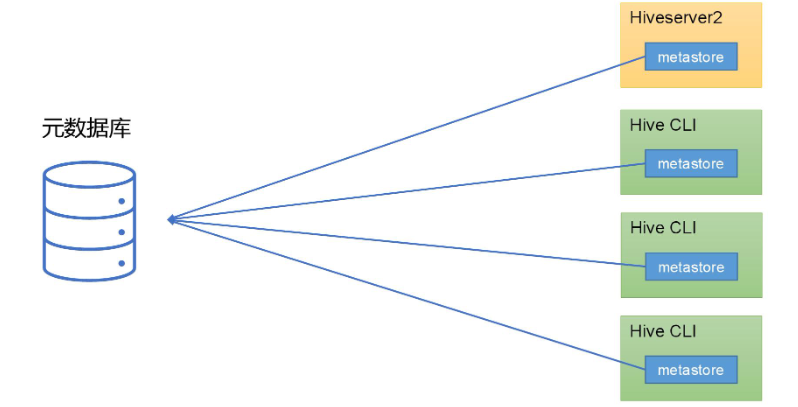
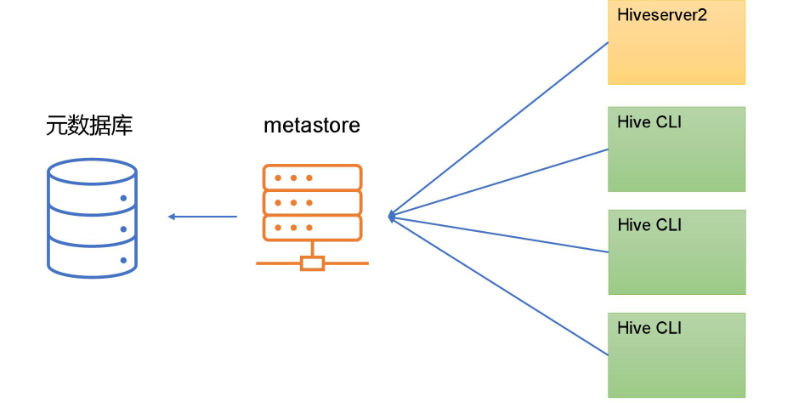
- 嵌入式模式下,每个HiveCLI都需要直接连接元数据库,当HiveCLI较多时,数据库压力会比较大。
- 每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证
- MetaStore的嵌入服务模式配置
- 嵌入式模式下,只需保证Hiveserver2和每个HiveCLI的配置文件hive-site.xml中包含连接元数据库所需要的参数即可
- MetaStore的独立服务模式配置
- 保证metastore服务的配置文件hive-site.xml中包含连接元数据库所需的参数
- 保证Hiveserver2和每个HiveCLI的配置文件hive-site.xml中包含访问metastore服务所需的以下参数
1 | <!-- 主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083 --> |
启动
hive --service metastore
Hive操作
- “-e”不进入hive的交互窗口执行hql语句
1 | hive -e "show databases" |
- “-f”执行hql文件
1 | hive -f /opt/module/hive/hive.sql |
- 用户自定义配置会覆盖默认配置,Hive的配置会覆盖Hadoop的配置
- 可以使用命令行参数设置,但是仅对本次hive启动有效
- 可以在交互式中用
set设置,但是仅对本次hive会话有效
DDL(Data Definition Language)
数据库操作
创建数据库
1 | -- 创建数据库 |
- IF NOT EXISTS:如果数据库不存在则创建
- COMMENT:数据库的注释
- LOCATION:数据库在HDFS上的存储路径
- WITH DBPROPERTIES:数据库的属性
查询数据库
1 | -- 查看所有数据库 |
修改数据库
1 | --修改dbproperties |
删除数据库
1 | -- RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。 |
切换数据库
1 | USE database_name; |
表操作
创建表
普通建表
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name |
TEMPORARY:临时表,会话结束后自动删除EXTERNAL:外部表,表的数据不会被删除,只会删除元数据,对应的是内部表,Hive会自动管理内部表的数据data_type:数据类型(注意多了复杂类型:array,map,struct)-
- 补充两种类型转换:
-
- 小范围类型可以转为更广的范围类型
-
- 显示转换需要使用cast函数
cast(expr as <type>)
- 显示转换需要使用cast函数
PARTITIONED BY:分区字段CLUSTERED BY,...,INTO BUCKETS:分桶字段ROW FORMAT:指定SERDE,SERDE是Serializer and Deserializer的简写。Hive使用SERDE序列化和反序列化每行数据。STORED AS:指定存储格式有,textfile(默认值),sequence file,orc file、parquet file等。LOCATION:指定表的存储路径若不指定路径,其默认值为${hive.metastore.warehouse.dir}/db_name.db/table_nameTABLEPROPERTIES:表的属性
ROW FORMAT说明
语法一:
DELIMITED关键字表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的SERDE对每行数据进行序列化和反序列化。
1 | ROW FORAMT DELIMITED |
- fields terminated by :列分隔符。
- collection items terminated by : map、struct和array中每个元素之间的分隔符。
- map keys terminated by :map中的key与value的分隔符。
- lines terminated by :行分隔符。
语法二:
SERDE关键字可用于指定其他内置的SERDE或者用户自定义的SERDE。例如JSON SERDE,可用于处理JSON字符串。
1 | ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, ...)] |
Create Table As Select(CTAS)创建表
1 | CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name |
该语法允许用户利用select查询语句返回的结果,直接建表,表的结构和查询语句的结构保持一致,且保证包含select查询语句放回的内容。
Create Table Like创建表
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name |
该语法允许用户复刻一张已经存在的表结构,与上述的CTAS语法不同,该语法创建出来的表中不包含数据。
查看表:
1 | -- 查看所有表 |
修改表:
1 | --重命名表 |
删除表:
1 | DROP TABLE [IF EXISTS] table_name; |
清空表:
1 | -- 仅删除表中数据,保留表结构,不能删除外部表 |
DML(Data Manipulation Language)
Load
Load语句可将文件导入到Hive表中
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]; |
(1)local:表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表。
(2)overwrite:表示覆盖表中已有数据,否则表示追加。
(3)partition:表示上传到指定分区,若目标是分区表,需指定分区。
Insert
- 将查询结果插入表中
1 | INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement; |
- 将给定的值插入表中
1 | INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...] |
- 将查询结果写入目标路径
1 | INSERT OVERWRITE [LOCAL] DIRECTORY directory |
Export&Import
Export导出语句可将表的数据和元数据信息一并到处的HDFS路径,Import可将Export导出的内容导入Hive,表的数据和元数据信息都会恢复。Export和Import可用于两个Hive实例之间的数据迁移。
1 | --导出 |
Hive查询语句
基础语法
1 | SELECT [ALL | DISTINCT] select_expr, select_expr, ... |
基础查询 & 分组查询
类似SQL
Join查询
join连接的作用,是通过连接键将两个表的列组合起来,用于将数据库中的两个或多个表的记录合并起来。join连接可以将其他表的列添加至连接主表,将两个表合并为一个宽表.
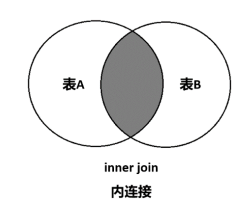
内连接
内连接中,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
- 使用内连接时,inner join中的inner关键字可以省略。
- 表名也可以用子查询替代。
- 当使用等号连接时,就是等值连接,当使用不等号时,就是不等值连接。
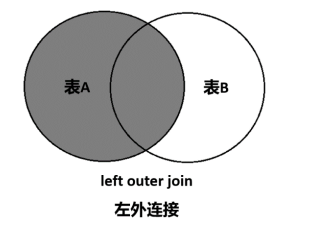
左外连接
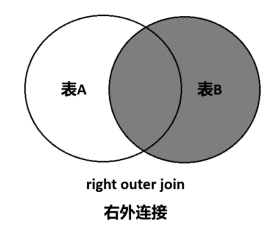
右外连接
全外连接
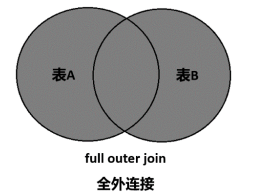
多表连接
oin除了可以实现2个表之间的连接外,还可以实现多表连接。
- 需要注意的是,连接n个表,至少需要n-1个连接条件。
- 大多数情况下,Hive会对每对join的连接对象启动一个MapReduce任务
- 对于多表连接中的每个表,如果在on子句中使用相同的列组成连接条件, Hive 会将多个表的连接转换为单个MapReduce任务
- 在多表连接时,表的连接顺序和选用的连接类型都会影响到最终的结果集
笛卡尔积
Hive中提供了cross join关键字,用于实现笛卡尔积
- 在hive.strict.checks.cartesian.product参数设置为true的严格模式下,以上语法是不能实现的,只有将该参数设置为false,以上语法才可以使用
- 在连接的每个 map/reduce 阶段,序列中的最后一个表会通过 reducer 进行流式传输,而其他表则会被缓冲。因此,通过合理安排join顺序,使得最大的表出现在序列的最后,有助于减少 reducer 中缓冲连接键的特定值的行所需的内存。如以下查询语句
联合(UNION)
1 | select_statement union [all | distinct] select_statement union [all | distinct] select_statement ... |
- union和union all都是将查询语句的查询结果上下联合,这点和join是有区别的,join是两表的左右连接,union和union all是上下拼接。
- union关键字会对联合结果去重,union all不去重。
- union和union all在上下拼接查询语句时要求,两个查询语句的结果,列的个数和名称必须相同,且上下对应列的类型必须一致。
排序查询
Order By
Order By:全局排序,只有一个 Reduce。
Sort By
Sort By:每个 Reduce 内部排序(写入文件能看出来)
- 对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局
排序,此时可以使用 Sort by。 - Sort by 为每个 reduce 产生一个排序文件。每个 Reduce 内部进行排序,对全局结果集
来说不是排序
Distribute By
Distribute By:在有些情况下,我们需要控制某个特定行应该到哪个 Reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MapReduce中 partition(自定义分区),进行分区,结合 sort by 使用。
- distribute by 的分区规则是根据分区字段的 hash 码与 reduce 的个数进行相除后,余数相同的分到一个区。
- Hive 要求 distribute by 语句要写在 sort by 语句之前。
Cluster By
当 distribute by 和 sort by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 asc 或者 desc。

函数
1 | -- 查看内置函数 |
单行函数
1 | -- 数值函数 |
1 | -- 集合函数 |
聚合函数
普通聚合
sum(),avg(),count(),max(),min(),...
高级聚合
1 | collect_set(col):返回一个集合,该集合包含了所有的groupby组内不重复的值 |
炸裂(UDTF)函数
UDTF的全称是User Defined Table-Generation Function,即用户定义的表生成函数。简单理解,UDTF就是接收一行数据,输出一行或者多行数据。系统内置的常用的UDTF有explode、posexplode、inline等
explode
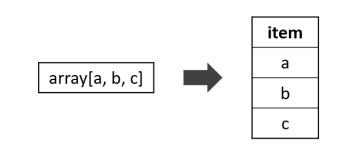
1 | -- 语法一:explode(array<T> a) |
posexplode
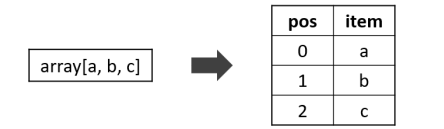
1 | -- posexplode(array<T> a)。 |
inline
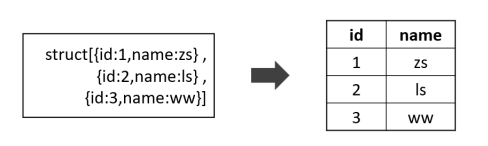
1 | -- inline(array<struct<f1:T1,...,fn:Tn>> a) |
lateral view
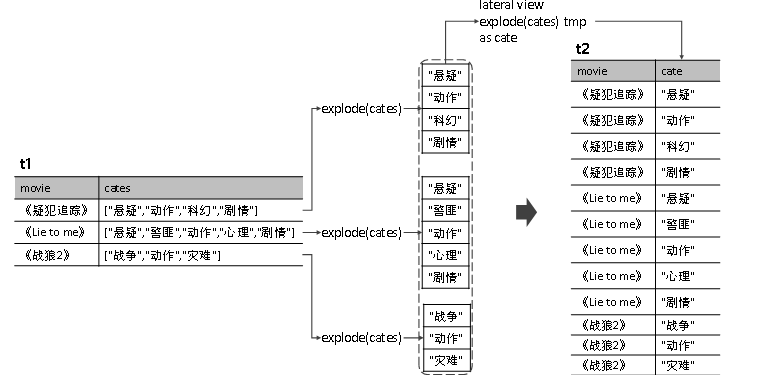
-
UDTF函数可以将一行数据转换为多行,出现在select语句中时,不能与其他列同时出现,会报如下所示错误信息。
-
lateral view可以将UDTF应用到原表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
-
lateral view一般在from子句后使用,紧跟在UDTF后面的是虚拟表的别名,虚拟表别名不可省略。as关键字后为执行UDTF后的列的别名,UDTF函数生成几列就要给出几个列别名,多个列别名间使用逗号分隔
1 | select |
窗口函数(开窗函数)
- 窗口函数能够为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。(类似pandas的rolling)
函数
- 每个窗口中的计算逻辑,都是多(行)进一(行)出,因此绝大多数的聚合函数都可以配合窗口使用
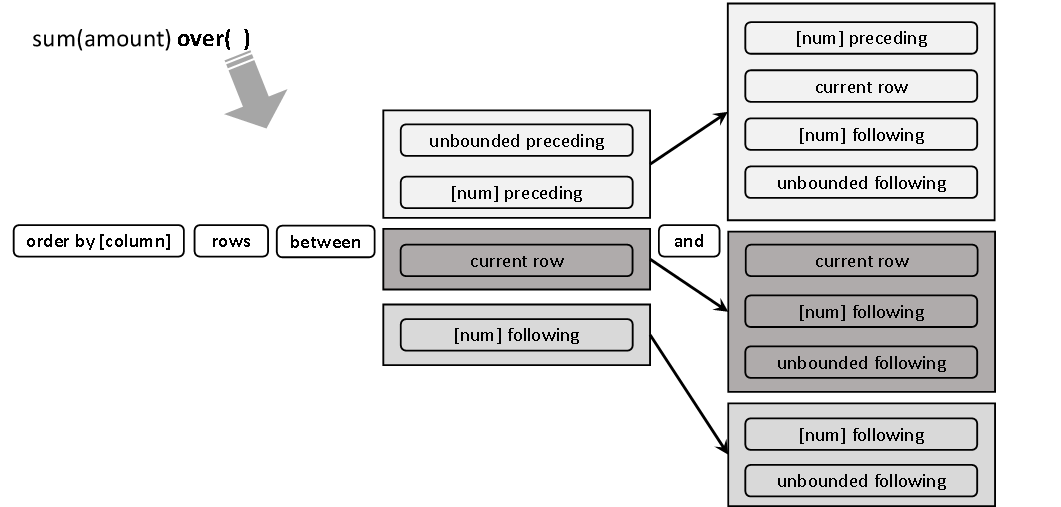
窗口
- 窗口范围的定义分为两种类型,一种是基于行进行定义,一种是基于值进行定义。它们都用来确定一个窗口中应该包含哪些行,但是确定的逻辑有所不同。
-
- 基于行的窗口范围定义,是通过行数的偏移量,来确定窗口范围,例如:某行的窗口范围可以包含当前行的前一行到当前行。
-
- 基于值的窗口范围定义,是通过某个列值的偏移量,来确定窗口范围,例如:若某行A列的值为10,其窗口范围可以包含,A列值大于等于10-1且小于等于10的所有行。
1 | -- 使用方法 |
1 | -- 基于行 |
分区
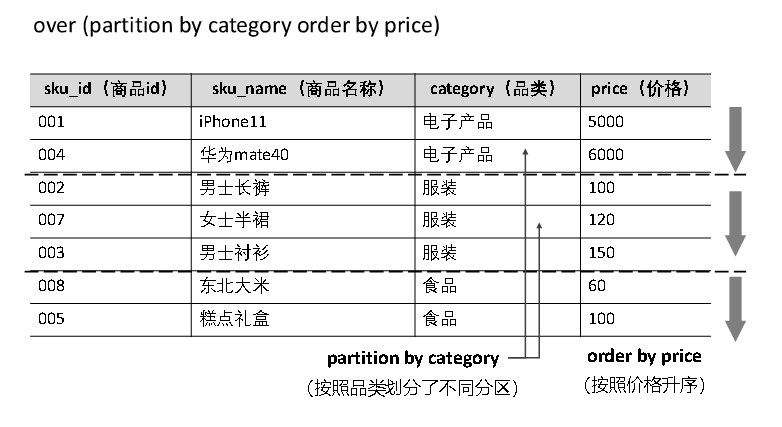
- 定义窗口范围时,还可以使用partition by关键字指定分区列,将每个分区单独划分为窗口。
- 每个分区内独立计算。
缺省
over后可以使用的窗口划分语句,都可以省略不写,包括:
- partition by
- order by
- (rows|range) between … and …。
- ①partition by省略不写,表示不分区。在不进行分区的情况下,将会把整张表的全部内容作为窗口进行划分。
- ②order by 省略不写,表示不排序。
- ③(rows|range) between … and … 省略不写,则使用其默认值,默认值分以下两种情况。
- 若over()中包含order by,则默认值为range between unbounded preceding and current row。
- 若over()中不包含order by,则默认值为rows between unbounded preceding and unbounded following。
常用窗口函数
- 聚合函数:
sum(),avg(),count(),max(),min() - 跨行取值函数
lead(col, n, default): 用于获取窗口内当前行往下第n行的值。lag(col, n, default): 用于获取窗口内当前行往上第n行的值。- lag和lead函数不支持使用rows between和range between的自定义窗口。
first_value (col, boolean):取分组内排序后,截止到当前行的第一个值。last_value (col, boolean):取分组内排序后,截止到当前行的最后一个值。- 第二个参数说明是否跳过null值,可不写。
- 排名函数:
rank()/dense_rank()/row_number()- 排名函数会对窗口范围内的数据按照order by后的列进行排名。
- rank 、dense_rank、row_number不支持自定义窗口
|score|rank|dense_rank|row_number|
|—|—|—|—|
|90|1|1|1|
|90|1|1|2|
|80|3|2|3|
|80|3|2|4|
|70|5|3|5|
自定义函数
根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出。
(2)UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出。
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
用户自定义表生成函数,一进多出。
如lateral view explode()
编程步骤:
- 继承Hive提供的类
- UDF:org.apache.hadoop.hive.ql.udf.generic.GenericUDF
- UDAF:org.apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver
- UDTF:org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
- 实现类中的抽象方法
- 在hive的命令行窗口中创建函数
- 临时函数:
-
- add jar xxx.jar
-
- create temporary function xxxxx as ‘xxx’
-
- select xxxxx(col) from table
-
- drop temporary function xxxxx;
-
- 临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
- 永久函数:
-
- 上传jar到HDFS
-
- create function xxxxx as ‘xxx’ using jar ‘hdfs://hadoop102:9000/xxx.jar’
-
- select xxxxx(col) from table
-
- drop function xxxxx
-
- 永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
-
- 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
自定义UDF函数
1 | // HQL转为MapReduce任务时,会生成Operator Tree(每个Operator都是一个小动作:扫描,select等) |
分区表和分桶表
分区
- 通过使用partitionedby子句可以创建分区表,partitionedby后面是分区字段,
- 一个表可以有一个或多个分区字段
- Hive可以为分区字段的每个不同的字段组合创建一个单独的数据目录(文件夹)
- 当用户通过where子句选择要查询的分区后,就不会查询其他分区的数据
- 分区字段并不是表中的数据,是伪列,可以当作列用
分区表基本操作
新建分区表
1 | -- 创建分区表 |
查看分区表
1 | show partitions dept_partition; |
增加分区
1 | -- 中间无逗号 |
删除分区
1 | -- 中间有逗号 |
修复分区
- Hive将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。
- 若用户在HDFS上手动创建/删除分区路径,Hive都是感知不到的,这样就会导致Hive的元数据和HDFS的分区路径不一致。
- 若分区表为外部表,用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除同样会导致Hive的元数据和HDFS的分区路径不一致。
1 | -- 若手动创建HDFS的分区路径,Hive无法识别,可通过add partition命令增加分区元数据信息,从而使元数据和分区路径保持一致。 |
二级分区
1 | -- 和一级分区类似,只是多了一个分区字段 |
动态分区
- 插入数据指定分区很麻烦
- 动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。
- 使用动态分区,可只用一个insert语句将数据写入多个分区。
- 插入语句的最后一个字段作为分区的字段,不需要指定分区字段,Hive会自动识别。
1 | -- 开启动态分区 |
分桶
-
分区提供一个隔离数据和优化查询的便利方式
-
对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分
-
分区针对的是数据的存储路径,分桶针对的是数据文件。
-
分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)。
基本语法
创建分桶表
1 | -- cluster by后面指定分桶字段,into后面指定分桶数 |
- 表中的文件数据会被分为四个桶,对应四个文件,每个文件中的数据都是根据id字段的hash值模4的结果相同的数据。
分桶排序表
- Hive的分桶排序表是一种优化技术,用于提高大数据存储和查询的效率。它将数据表按照指定的列进行分桶(bucket),每个桶内的数据再按照指定的列进行排序,这样就可以在查询时快速定位到需要的数据,减少数据扫描的时间。
- 使用分桶排序表的主要优点是可以提高查询效率,特别是在大数据量的情况下。相比于无序表,分桶排序表在查询时可以跳过不需要的数据,减少数据扫描的时间。
1 | -- clustered by关键字指定按照哪个列进行分桶,sorted by关键字指定在每个桶内按照哪个列进行排序。 |
文件格式和压缩
文件格式
- 在创建表时,使用关键字
stored as 文件格式[textfile|sequencefile|orc|parquet]指定文件格式。 - 使用列式存储格式(orc和parquet)的查询性能和存储效率都要优于默认的文本文件格式,其中orc的性能略微优于parquet。
TextFile
- 文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。
ORC
-
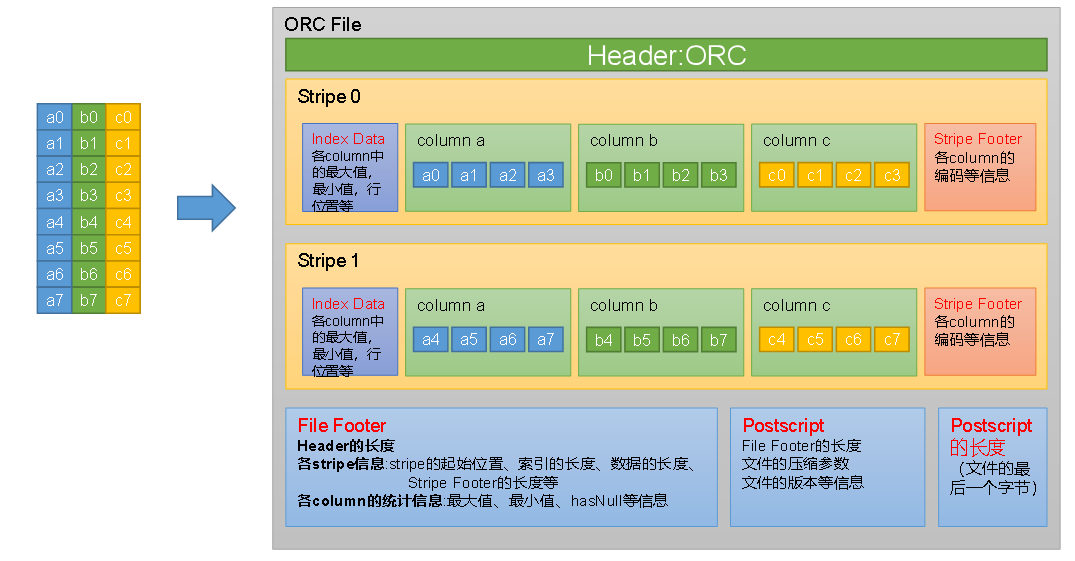
ORC是一种列式存储的文件格式,ORC文件能够提高Hive读写数据和处理数据的性能
-
列式存储(操作系统里的文件排列方式)
-
每个Orc文件由Header、Body和Tail三部分组成。
-
Body由1个或多个stripe组成(HRegion),每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,每个stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer。
-
- Index Data:一个轻量级的index,默认是为各列每隔1W行做一个索引。每个索引会记录第n万行的位置,和最近一万行的最大值和最小值等信息。
-
- Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream来存储。
-
- Stripe Footer:存放的是各个Stream的位置以及各column的编码信息
-
Tail由File Footer和PostScript组成。
-
- File Footer中保存了各Stripe的其实位置、索引长度、数据长度等信息,各Column的统计信息等;
-
- PostScript记录了整个文件的压缩类型以及File Footer的长度信息等。
-
在读取ORC文件时,会先从最后一个字节读取PostScript长度,进而读取到PostScript,从里面解析到File Footer长度,进而读取FileFooter,从中解析到各个Stripe信息,再读各个Stripe,即从后往前读。
建表
1 | create table orc_table |
| 参数 | 默认值 | 说明 |
|---|---|---|
| orc.compress | ZLIB | 压缩格式,可选项:NONE、ZLIB,、SNAPPY |
| orc.compress.size | 262144 | 每个压缩块的大小(ORC文件是分块压缩的) |
| orc.stripe.size | 67108864 | 每个stripe的大小 |
| orc.row.index.stride | 10000 | 索引步长(每隔多少行数据建一条索引) |
Parquet
-
Parquet也是一个列式存储的文件格式。
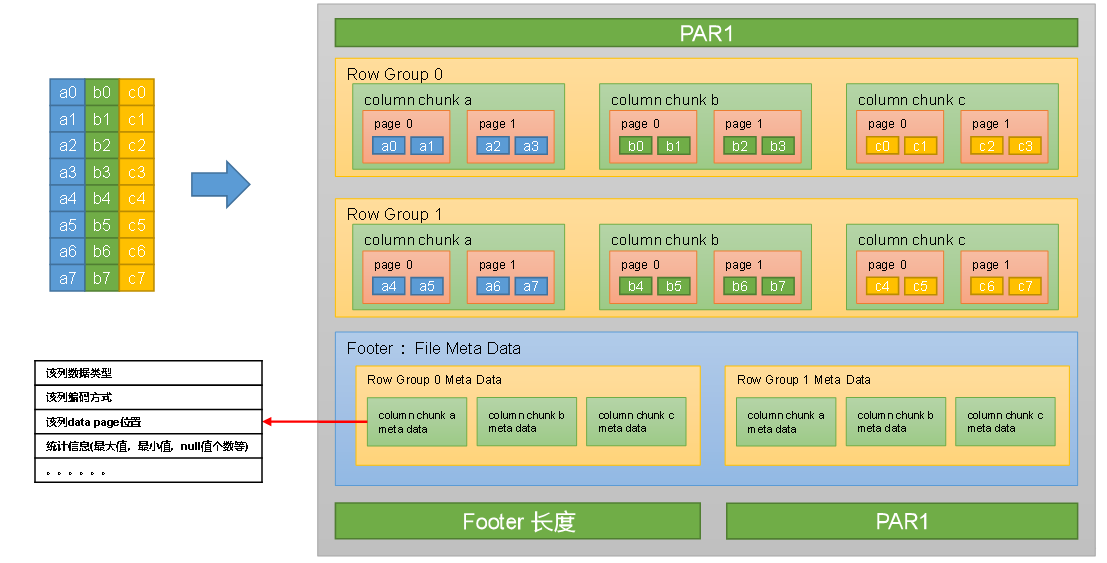
-
文件的首尾都是该文件的Magic Code,用于校验它是否是一个Parquet文件。
-
首尾中间由若干个Row Group和一个Footer(File Meta Data)组成。
-
每个Row Group包含多个Column Chunk,每个Column Chunk包含多个Page。
-
- 行组(Row Group):一个行组对应逻辑表中的若干行。
-
- 列块(Column Chunk):一个行组中的一列保存在一个列块中。
-
- 页(Page):一个列块的数据会划分为若干个页。
-
Footer(File Meta Data)中存储了每个行组中的每个列快的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。
建表
建表语句和ORC类似
| 参数 | 默认值 | 说明 |
|---|---|---|
| parquet.compression | uncompressed | 压缩格式,可选项:uncompressed,snappy,gzip,lzo,lz4 |
| parquet.block.size | 134217728 | 行组大小,通常与HDFS块大小保持一致 |
| parquet.page.size | 1048576 | 页大小 |
压缩
- 在Hive表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。
Hadoop中的压缩格式
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
对Hive数据表进行压缩
TextFile
1 | - 若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时,可自动识别其压缩格式,进行解压。 |
ORC和Parquet
若一张表的文件类型为ORC/Parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
1 | create table orc_table |
计算过程中使用压缩
单个MR的中间结果压缩
单个MR的中间结果是指Mapper输出的数据,对其进行压缩可降低shuffle阶段的网络IO,
1 | --开启MapReduce中间数据压缩功能 |
单条SQL的中间结果压缩
单条SQL语句的中间结果是指,两个MR(一条SQL语句可能需要通过MR进行计算)之间的临时数据
1 | --是否对两个MR之间的临时数据进行压缩 |
★企业级调优
Yarn资源配置
- YARN的内存调优的相关参数可以在yarn-site.xml文件中修改,需要调整的YARN参数均与CPU、内存等资源有关
1 | <!-- (1)yarn.nodemanager.resource.memory-mb --> |
MapReduce资源配置
- MapReduce资源配置主要包括Map Task的内存和CPU核数,以及Reduce Task的内存和CPU核数。
1 | 1)mapreduce.map.memory.mb |
Explain查看执行计划
Explain执行计划概述
- Hive中可以使用explain命令来查看Hive SQL的执行计划,
- 用户通过分析执行计划可以看到该条HQL的执行情况,了解性能瓶颈,最后对Hive SQL进行优化。
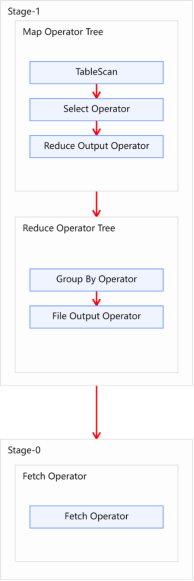
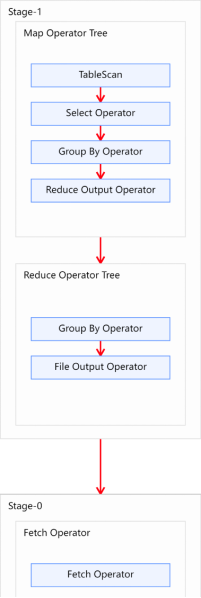
- Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
- 若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作
-
- TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
-
- Select Operator:选取操作
-
- Group By Operator:分组聚合操作
-
- Reduce Output Operator:输出到 reduce 操作
-
- Filter Operator:过滤操作
-
- Join Operator:join 操作
-
- File Output Operator:文件输出操作
-
- Fetch Operator 客户端获取数据操作
Explain语法
1 | EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql |
- FORMATTED:将执行计划以JSON字符串的形式输出
- EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
- DEPENDENCY:输出执行计划读取的表及分区
Explain输出结果解读
1 | explain |

1 | STAGE DEPENDENCIES: |
分组聚合优化
优化说明
- Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。
- Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
- Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。
- 所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。
- map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
- map-side,理解为MapReduce中的Combiner
1 | --启用map-side聚合 |
★Join优化
Join算法介绍
Common Join
- Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。
- Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
- sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
- sql语句中的两个join操作关联字段各不相同,则该语句的两个join操作需要各自通过一个Common Join任务实现,也就是通过两个Map Reduce任务实现。
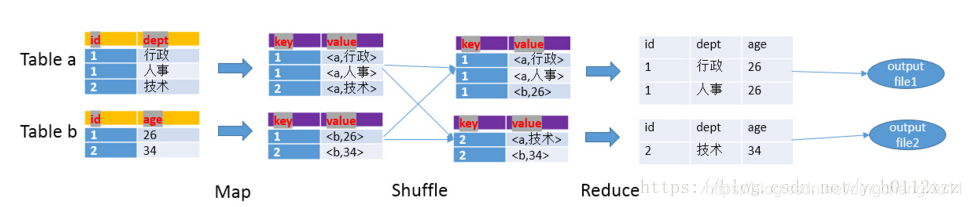
-
Map阶段
- 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
- Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
- 按照key进行排序
-
Shuffle阶段
- 根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- 一个reduce中可能会处理多个key
-
Reduce阶段
- 根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
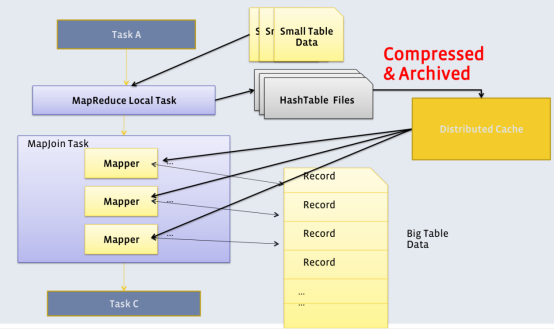
Map Join
- Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。
- 若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。
- 第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。
- 类似Hadoop案例中的Join案例
Bucket Map Join
- Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
- 若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。
- 这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。
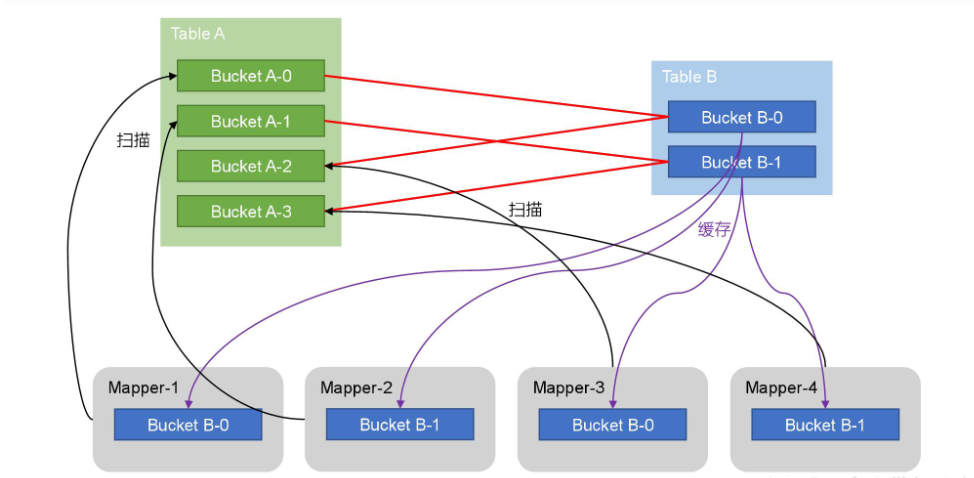
- tableA的BucketA-0和BucketsA-2 与 tableB的BucketB-0 key是一样的(因为取模都为偶数)
- 所以tableA的BucketA-0的Mapper直接拉取tableB的BucketB-0的数据(hash table缓存),进行join操作
Sort Merge Bucket Map Join
- SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
- SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作
- Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
- SMB Map Join在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
Map Join优化
1.手动Hint触发(过时)
1 | select /*+ mapjoin(ta) */ |
2.自动触发
- Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。
- 之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
- Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。最终具体采用哪个计划,是在运行时决定的。
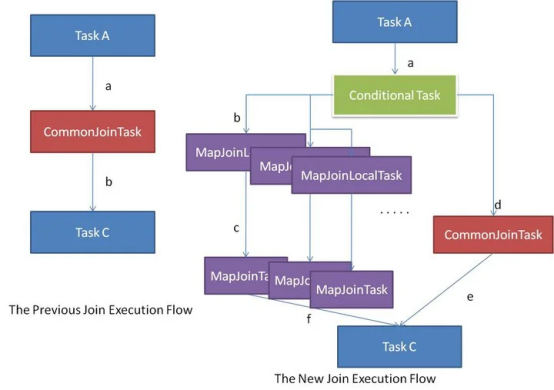

1 | --启动Map Join自动转换 |
流程讲解
- 是否启用自动转换,false则用Common Join
- 根据Join的方式查看是否有满足条件的大表,没有大表则用Common Join
- 判断是否启用条件任务
- 启用条件任务:
- 尝试以每个大表候选人作为大表生成map join计划
- 如果大表候选人的大小已知,且其他已知表大小总和大于hive.mapjoin.smalltable.filesize(不是小表),则不生成map join计划
- 如果最终没有生成map join计划,则使用Common Join
- 如果有生成map join计划,将所有的map join计划和common join计划放入人物列表
- 最终的执行计划是在运行时决定的
- 不启用条件任务:
- 某个大表候选人的大小已知,且其他已知表大小总和小于hive.auto.convert.join.noconditionaltask.size,如果为false(其他表总和太多大),则自动转向条件任务
- 生成最优计划,如果子任务也是map join(对应三个表的join),且子任务和当前任务的所有小表都小于hive.auto.convert.join.noconditionaltask.size,false则不合并,
- true则合并为一个map join任务(两个小表)
Map Join优化案例
1 | select |
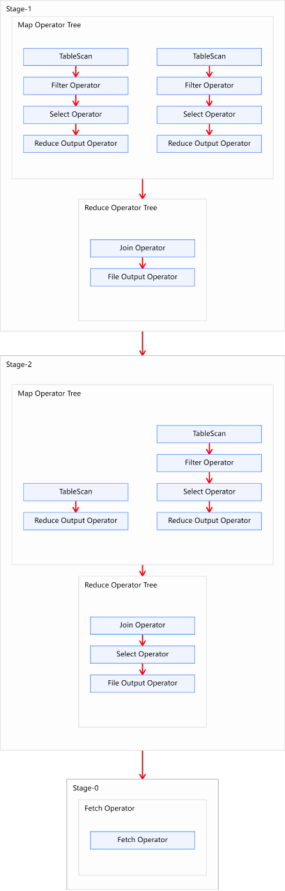
- 无任何优化
- 第一个join执行了一个Common Join,第二个join执行了一个Common Join
方案一
1 | -- 启用Map Join自动转换。 |
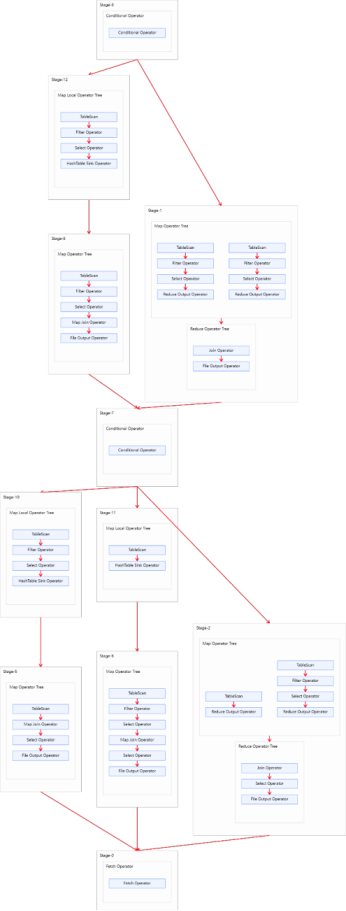
- 会走条件转换,分多个Map Join任务
方案二
1 | -- 启用Map Join自动转换。 |
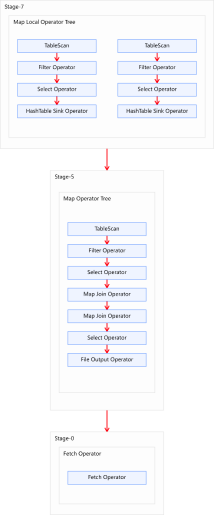
- 直接将两个Common Join operator转为两个Map Join operator,
- 并且由于两个Map Join operator的小表大小之和小于等于hive.auto.convert.join.noconditionaltask.size,故两个Map Join operator任务可合并为同一个
*方案三
1 | -- 启用Map Join自动转换。 |

- 这样可直接将两个Common Join operator转为Map Join operator,但不会将两个Map Join的任务合并。
Bucket Map Join优化
- Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用。
1 | -- Hint提示 |
order_detail和payment_detail是没有分桶的
1 | select |
先分桶
1 | --订单表 |
重写SQL
1 | select /*+ mapjoin(pd) */ |
- 详细执行计划中,如在Map Join Operator中看到 “BucketMapJoin: true”,则表明使用的Join算法为Bucket Map Join。
Sort Merge Bucket Map Join优化
配置自动优化参数
1 | --启动Sort Merge Bucket Map Join优化 |
Join优化总结
在条件优化中的参数:
1 | --一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。 |
- 这两个条件的大小代表的表的实际大小,不是内存大小
- 内存大小与实际大小的比值经验约为:10:1,因为要有类对象信息等
- Bucket Map Join 分多少桶要根据Map的内存大小来决定一个桶的大小约50M差不多
★数据倾斜优化
- 数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
- 常见于分组聚合和join操作的场景中
分组聚合导致的数据倾斜
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
第一种:Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。
类似Combiner
1 | --启用map-side聚合 |
第二种:Skew-Groupby优化
- Skew-GroupBy的原理是启动两个MR任务,
- 第一个MR按照随机数分区,将数据分散发送到Reduce(均匀的,因为是随机数),按随机数完成部分聚合,
- 第二个MR,拿到第一个Reduce的输出(部分聚合,减少了key的数量),按照分组字段分区,完成最终聚合。
1 | --启用分组聚合数据倾斜优化 |
Join导致的数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
第一种:map join优化
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。
第二种:skew join优化
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。
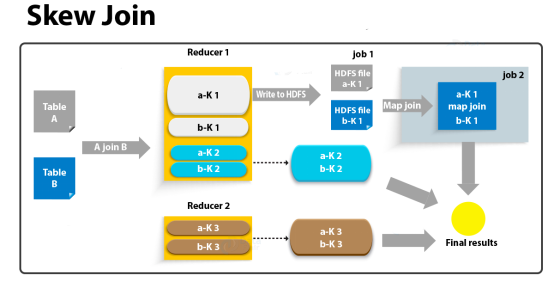
- 刚开始是一个common join,在reduce中检测到数据倾斜
- 将数据(A表和B表)写到HDFS中,然后启动一个map join任务
- 将小表数据读取到内存中,大表数据切片,每个map一个切片处理
1 | --启用skew join优化 |
第三种:优化SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
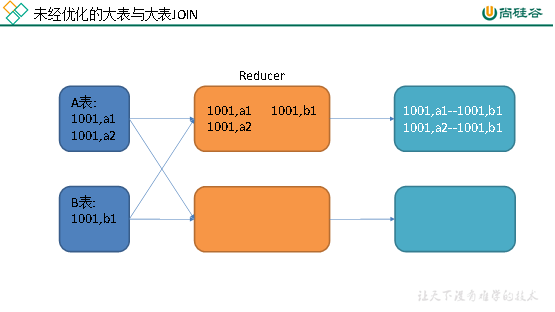
1 | select |
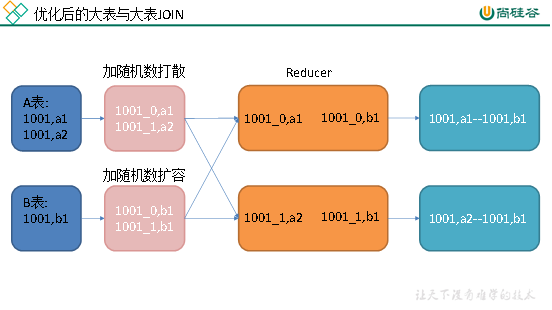
1 | select |
任务并行度优化
Map端
- Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。
- 以下情况下,可以考虑调整Map端的并行度:
- 查询的表中存在大量小文件
-
- 使用Hive提供的CombineHiveInputFormat,多个小文件合并为一个切片,从而控制map task个数
-
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- map端有复杂的查询逻辑
-
- 若SQL语句中有复杂耗时的查询逻辑时,map端的计算会相对慢一些。可令map task多一些,每个map task计算的数据少一些。
-
set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce端
- Reduce端的并行度,可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算。
1 | --指定Reduce端并行度,默认值为-1,表示用户未指定 |
若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive自行估算Reduce并行度,估算逻辑如下:
假设Job输入的文件大小为totalInputBytes
参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer。
参数hive.exec.reducers.max的值为maxReducers。
则Reduce端的并行度为:
自动估算存在的问题
- Hive自行估算Reduce并行度时,是以整个MR Job输入的文件大小作为依据的。
- 整个文件的输入大小,和Map端输出的大小不一定一致,甚至差距很大(map side)
小文件合并优化
Map端输入的小文件合并
1 | --可将多个小文件切片,合并为一个切片,进而由一个map任务处理 |
Reduce端输出的小文件合并
- 合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。
- 其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。
1 | --开启合并map only任务输出的小文件 |
其他优化
CBO优化
CBO(cost based optimizer),基于成本的优化
- 在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。
- Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。
- 主要用于join的join顺序
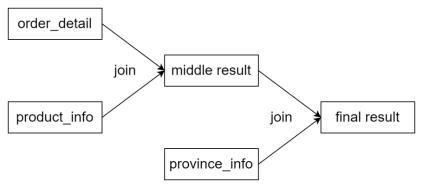
优化前
优化后
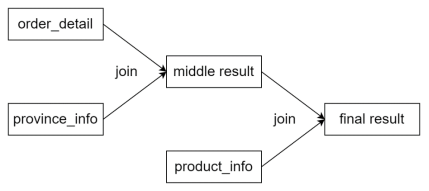
- 三表join,三个表个最后的result都一样,区别在于中间的middle表
- CBO优化使得中间结果尽可能小,减少内存使用(product_info是大表)
谓词下推
- 谓词下推是指将Hive SQL中的过滤条件下推至数据源,以减少数据的读取量,提高查询效率。
- CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低
1 | --是否启动谓词下推(predicate pushdown)优化 |
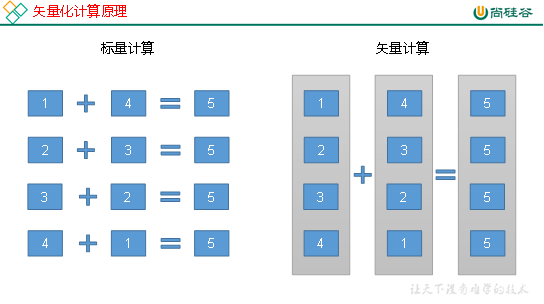
矢量化查询
- Hive的矢量化查询优化,依赖于CPU的矢量化计算
- 矢量化查询减少了cpu计算的频次
1 | set hive.vectorized.execution.enabled=true; |
Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。
1 | --是否在特定场景转换为fetch 任务 |
本地模式
- 大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。
- 不过,有时Hive的输入数据量是非常小的。
- 在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。
- 对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。
- 对于小数据集,执行时间可以明显被缩短。
1 | --开启自动转换为本地模式 |
并行执行
- Hive会将一个SQL语句转化成一个或者多个Stage,每个Stage对应一个MR Job。
- 默认情况下,Hive同时只会执行一个Stage。但是某SQL语句可能会包含多个Stage,但这多个Stage可能并非完全互相依赖,也就是说有些Stage是可以并行执行的。
- 此处提到的并行执行就是指这些Stage的并行执行。
1 | --启用并行执行优化 |
严格模式
- Hive可以通过设置某些参数防止危险操作
分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reduce中进行处理,强制要求用户增加这个limit语句可以防止Reduce额外执行很长一段时间(开启了limit可以在数据进入到Reduce之前就减少一部分数据)。
禁止使用笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
