Few-shot Object Detection
综述
Few-Shot Object Detection: A Comprehensive Survey
- 问题定义:N-way K-shot表示使用K个样本来训练N个类别
- 和few-shot learning,semi-supervised learning,increamental learning的区别
- 使用到的技术:1)迁移学习2)度量学习3)元学习
Dual-Branch meta learning:
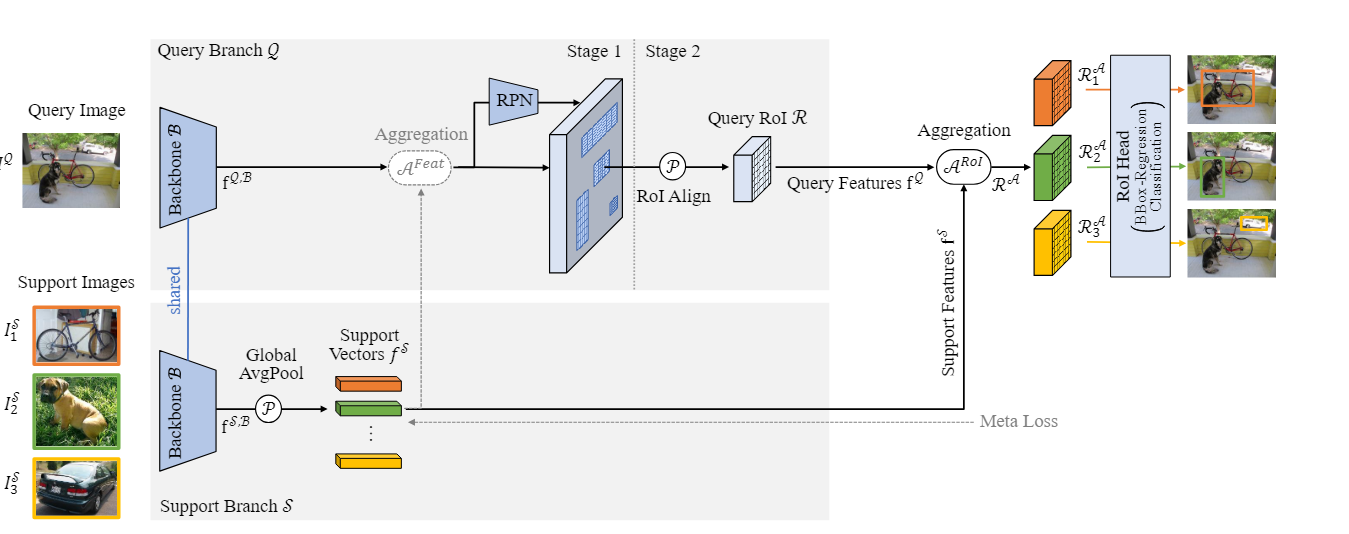
实现思路:一个Query Branch用来提取待检测图像的特征,然后通过RPN和一个RoI Align得到Query Feature,再和Support Feature提取出来的Support特征(K shot,K>1取平均),进行Aggregation,然后送入RoI Head进行分类和回归.
-
聚合相关改进
- Variant For Aggregation:
- 缺点:在RPN之后进行聚合,需要RPN为新类别生成Proposal,但是RPN可能无法为新类别生成Proposal
- 改进:在RPN之前进行聚合(AttentionRPN),然后将增强的特征送入RPN,生成Proposal
- 改进:使用second-order pooling替换avg pooling,减少Support Feature的颜色,条纹,斑点带来的噪声
- Variant For Aggregation Operation
- 缺点:简单的channel-wise 乘法不能充分利用Query和Support的特征
- 改进:添加比例因子,使用卷积,利用更复杂的操作等
- Keep Spatial Information for Aggregation
- 缺点:average pooling会丢失空间信息,convolution会导致空间信息不对齐
- 改进:attention-based aggregation
- Attention-base Aggregation
- Dual-Awareness Attention for Few-Shot Object Detection:增强前景,抑制背景并使用Query Feature Map促进空间位置的对齐
- Object detection based on few-shot learning via instance-level feature correlation and aggregation:IFC module用于构造实例特征的相关性,ASA module增强查询和支持之间的特征灵敏度,减少冗余信息
- Few-shot object detection with affinity relation reasoning:设计了一个亲和关系推理模块(ARRM)来促进支持特征和感兴趣区域特征的交互
- One-Shot Object Detection with Co-Attention and Co-Excitation:使用非局部操作来探索每个查询-目标对中体现的共同注意,并且使用改进的SeNet分配候选区域的重要性
- Adaptive Image Transformer for One-Shot Object Detection:将支持和查询作为Transformer的输入,来充分融合信息
- Multi-Level Aggregation
- 缺点:只在特征抽取之后进行了一次聚合
- 改进:使用PVTv2(Pyramid Vision Transformer)在特征抽取的时候进行多次融合
- Aggregation of Several Support Images
- 缺点:多个Support Image的情况下,对特征图取平均,忽略了不同的信息
- 改进:1)使用可学习的权重 2)使用softmax分配权重
- Variant For Aggregation:
-
Incorporate Relation between Caregories
- 缺点:基本类别可以帮助识别新的稀疏类
- 改进:1)融入语言特征 2)构建图关系(多类别关系增强特征,合并相似类别特征) 3)捕获类间相似性,增强泛化能力
-
Increase Discriminative power
- 缺点:1)在聚合之后,通常使用交叉熵损失判别分类,更好的方法是使用度量学习 2)元学习学习去区分前景和背景,这导致有可能检测到不存在的物体
- 改进:-1)GenDet和Meta DETR通过相似度矩阵最小化类间差异,最大化不同的支持向量 2)MM-FSOD使用皮尔斯系数聚合支持向量和查询向量 3)CME擦除最具辨别力的像素 -1)AttentionRPN使用多关系检测器来判断是否存有物体 2)对比学习测量用来区分不同的类别 3)GenDet使用额外的检测器检测基类,增强骨干网络提取更具代表性的特征
-
Improve representation capability
- 缺点:base categories被视为负类,导致识别新类的表达能力不足
- 改进:SPCN通过选择与基类不同的区域,并使用自监督的方式检测数据增强前后相同的非基类区域
-
Proposal-free Detector
- 缺点:许多方法基于Faster RCNN,1)可能生成不准确的区域建议框,2)决定在区域建议框之前还是之后进行聚合
- 改进:1)无提议框的模型更容易实现 2)基于YOLO 3)基于DETR
-
Keep the Performance on Base Categories
- 缺点:学习新的类别之后,模型可能会导致灾难性遗忘
- 改进:1)Meta Faster R-CNN使用一个额外的branch预测base categories,在训练期间固定 2)Sylph每个类别使用独立的分类器
-
Increase the Variance of Novel Categories
- 缺点:直接应用数据增强效果不佳
- 改进:TIP使用additional transformed guidance consistency loss,使得变化前后的图像特征保持一致
-
Incorporate Context Information
- 缺点:在RoI pool或者RoI Align之后,可能导致丢失信息
- 改进:DCNet使用三种不同分辨率执行并行池化
-
Category-agnostic Bounding Box Regression
Single-Branch meta learning:
用的太少,且精确度不高
Transfer Learning
略…
- Modifications of the Region Proposal Network
- Modifications of the Feature Pyramid Network
- Increase the Variance of Novel Categories
- Transfer Knowledge Between Base and Novel Categories
- Keep the Performance on Base Categories
- Modify the Training Objective
- Use Attention
- Modify Architecture
论文

1. (MetaYOLO,FSRW) Few-shot Object Detection via Feature Reweighting
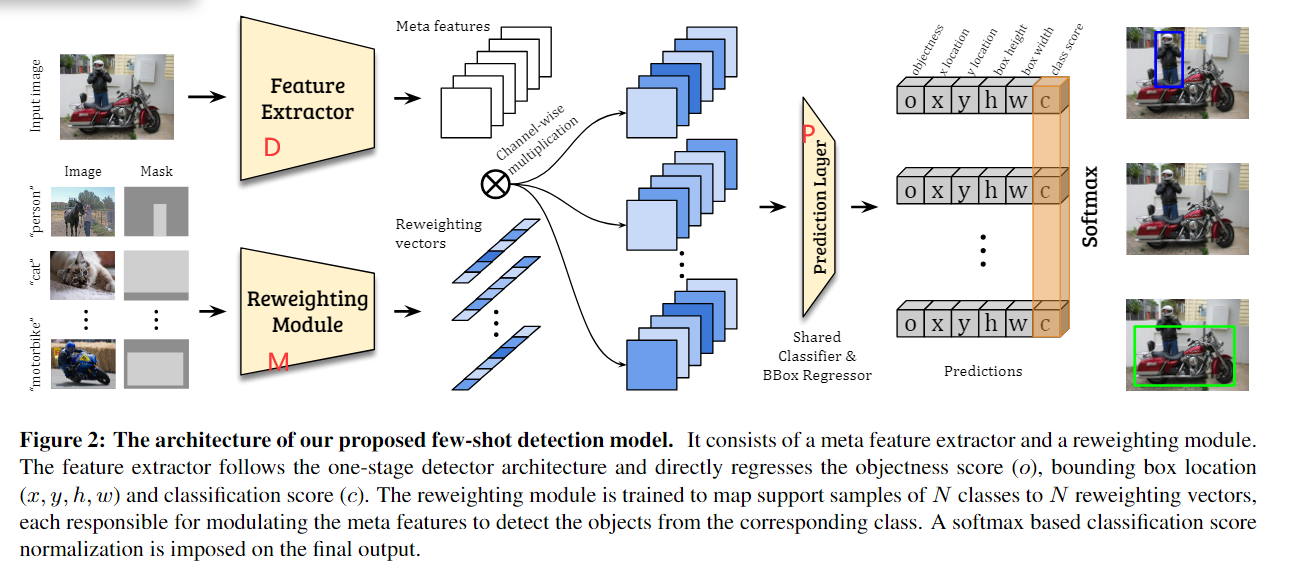
思想:
- 一个元特征抽取模块(meta feature extractor:YOLOv2中的Darknet19),用来提取查询图像的元特征
- 一个特征重加权模块(feature reweighting module),将支持图像抽取出全局特征(class-specific representation),用于调整元特征的贡献,获得(理解为抽取出支持图像的特征然后和查询图像的特征做一个channel-wise的乘法,来形成一个reweighting的特征(class-specific features)).
另一个理解:把支持图像的特征抽取成一个权重参数,用这个参数来动态调整查询图中的特征贡献,得到一个新的class-specific features - 将class-specific features送入YOLOv2的检测器中进行检测
- 输入是一个图形和二进制掩码,掩码只支持一个目标
训练:
- 基础训练阶段,正常目标检测训练,目的是让模型学会通过参考reweighting向量来检测感兴趣的预取
- 微调训练阶段,在基类和新类上训练模型,每个类K个support images, 模拟K-shot
- 损失函数中的分类损失,使用softmax之后的类别
2. (MetaRCNN) Meta R-CNN: Towards General Solver for Instance-Level Low-Shot Learning
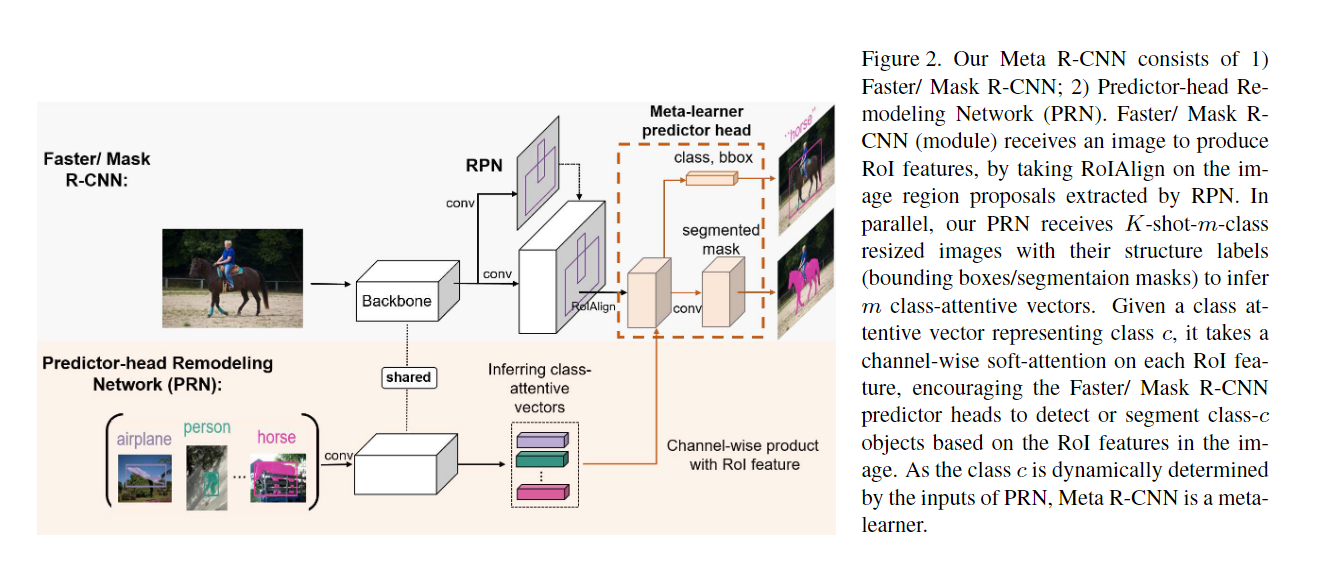
思想:
- 查询集图片经过特征提取网络和RPN网络(与Faster/Mask R-CNN中相同)得到感兴趣区域的特征图。
- 支持集图像和对应的真实标签图经过预测器重建模网络(Predictor-head Remodeling Network)得到每个类别对应的类别注意力向量(class-attentive vectors),PRN网络的主体部分与Faster/Mask R-CNN的特征提取网络结构相同且权重共享,得到对应特征图后,通过逐元素Sigmoid函数得到对应的注意力向量.
- 最后将RPN网络输出的感兴趣区域特征图和PRN网络输出的注意力向量通过逐通道相乘的方式进行融合,再利用Faster/Mask R-CNN中预测头得到对应个检测图或分割图.
符号说明:
| 含义 | 含义 | 含义 | 含义 |
|---|---|---|---|
| 基类 | 新类 | ||
| 基类新类的混合 | |||
| 训练数据 | 测试数据 | ||
| 原始预测头 | 重建后的预测头 |
PRN:
PRN从中推断类别注意向量. 具体而言,PRN输入的是一系列物体的图像,共个类别,每类个样本,每个物体由RGB图像和前景掩码标记四个通道表示,经过一层卷积之后,送入共享参数的backbone,最后经过通道软注意力生成目标注意力向量,经过平均池化得到类别注意向量,将其与 RoI 特征()进行通道层级的点乘,将转为
$ h\left(\hat{\mathbf{z}}{i, j}, D{\text {meta }} ; \boldsymbol{\theta}^{\prime}\right) \= h\left(\hat{\mathbf{z}}{i, j} \otimes \mathbf{v}^{\text {meta }}, \boldsymbol{\theta}\right) \=h\left(\hat{\mathbf{z}}{i, j} \otimes f\left(D_{\text {meta }} ; \boldsymbol{\phi}\right), \boldsymbol{\theta}\right) $
关键点:
- Mini-batch construction:
- 一个训练的mini-batch包含 m个类,K-shot m-class的meta-set (测试数据), m个类的训练数据 . 就是Faster RCNN的输入对象.
- Channel-wise soft-attention layer
- 执行空间池化来对齐图像特征,保持相同大小的Roi特征(),特征经过逐元素的 sigmoid 以产生注意力向量
- Meta-loss
- 不同类对象的注意向量应该导致对Roi特征的不同选择,为此提出一个,使元学习中推断的对象注意力向量多样化。通过交叉熵损失实现的,鼓励对象注意力向量落在每个对象所属的类中
- Roi meta-learning
- 训练分为两部分,1. meta-train:只使用基类对象构建 2.meta-test:使用基类和新类对象构建
- inference
- 训练时的object attentive vectors将替换class-attentive vectors,用于在Roi特征上作用sotf-attention
- 在测试时,PRN接受K-shot来生成class-attentive vectors,然后用于Roi特征上的soft-attention.但是测试时,class-attentive vectors可以提取预处理,然后用于Roi特征上的soft-attention.
补充
Deep Traffic 微信公众号:Meta-RCNN
补充
3. (AttentionRPF) Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
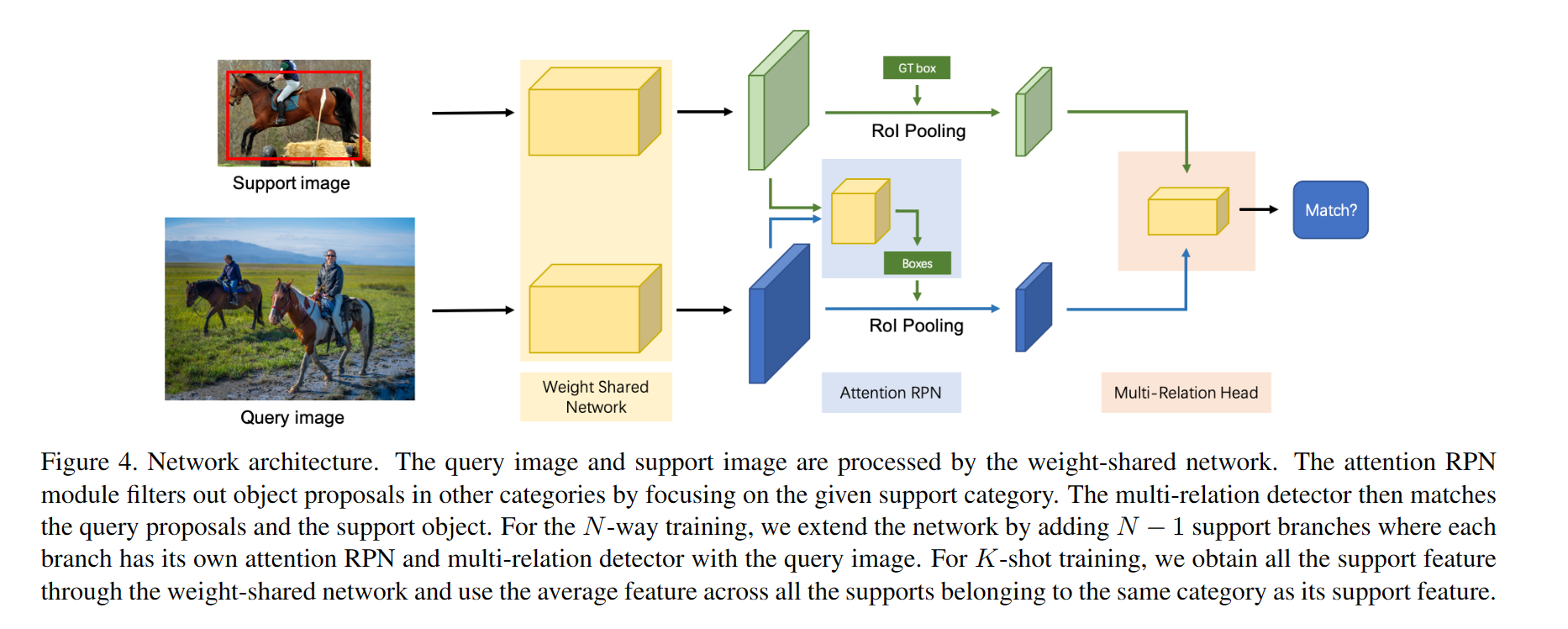
思想:
- Attention-RPN:通过注意力机制向 RPN 引入支持信息来指导 RPN 产生相关的候选框,抑制其他类别的候选框.将support feature变成的向量(作者发现s=1效果最好,就是1×1的卷积核),然后在query feature上进行卷积,建立注意力map(这种卷积其本质是按通道的点积,可以视为求余弦相似度的过程),然后将这个注意力map经过一个卷积送到RPN中.
- Multi-Relation Detector:测量来自查询和支持对象的提议框之间的相似性,分类三个(全局关联,局部关联,以及patch关联);最终得到的是支持对象和候选框直接的匹配得分(matching score).
- 对比实验,提出相同类别的对象重要,不同类别的对象更重要.构建了一个三元组(查询对象类比,支持对象类别,支持对象其他类别),来增强模型对前景和背景的区分能力.
解决:
- RPN对novel class的提议不好
- 现有的模型都需要fine-tune
Deep Traffic 微信公众号:Attention-RPN
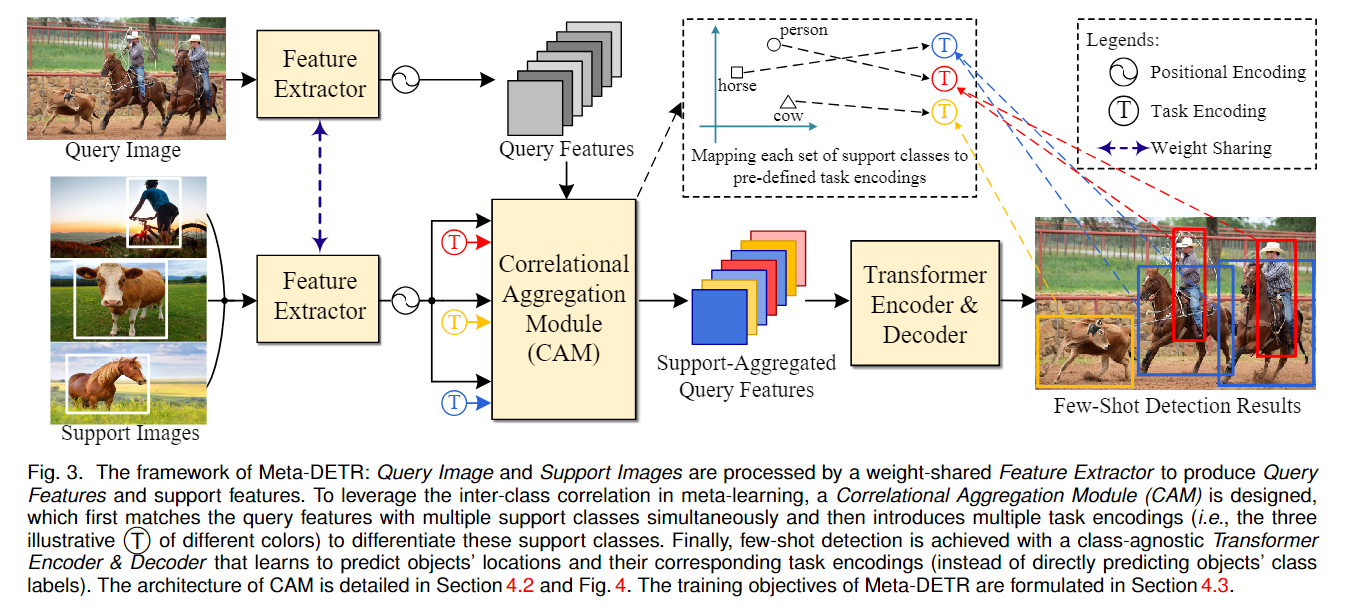
4. (MetaDETR) Meta-DETR: Image-Level Few-Shot Object Detection with Inter-Class Correlation Exploitation
问题:
- 低质量的新类区域建议
- 单次推理只能检测一个类,忽略了不同类的类间相关性
思想:
- 共享的特征抽取器把查询图像和支持图像提取到相同的特征空间中
- 通过相关聚合模块(CAM)执行查询和支持直接的匹配,CAM进一步把支持类映射到一组预定义的任务编码中,这些任务编码以类无关的方式区分支持类
- 最后,通过transformer架构(Deformable-DETR)预测对象位置和相应任务编码
关键点:
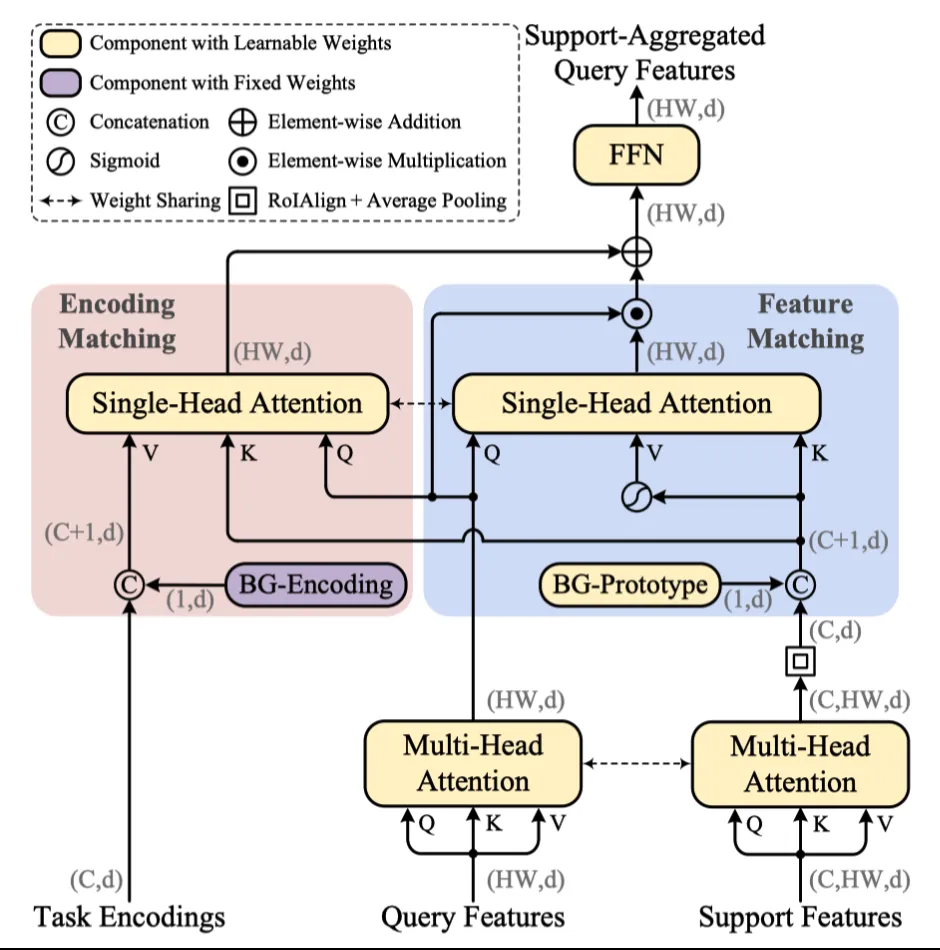
-
Feature Matching:通过稍微修改注意力机制实现特征匹配,旨在过滤掉与支持类无关的特征;
-
Encoding Matching:为了实现相关元学习,给每个支持类的预定义任务编码,并将查询特征与其对应的任务编码进行匹配,以便可以对任务编码而不是特定类进行最终预测。
- 此处的任务编码就是Transformer中的正弦函数位置编码
-
Modeling Background for Open-Set Prediction,给背景一个支持占位和任务编码
训练:
- 给定一个查询图像,随机抽取代表不同支持类的K张支持图像。只保留属于采样支持类的Ground Truth真实标注框作为检测目标。此外,每个对象的分类目标是真是标注类的任务编码,而不是真实标注类本身。
- 标注类转任务编码:,具体实现不重要…
- 最终的任务是:将目标类的标签映射到相应任务编码的标签
代码:
Meta-DETR
理解:
- 作者没有把CAM单独抽取出来一个模块(找不到命名为CAM的模块),而是继承DeformableDETR,整个模型就是一个DeformableDETR,CAM就是DeformableDETR的Encoder的第一个层,(就是
DeformableTransformermodel中的第一个TransformerEncoderLayer) - CAM的实现核心代码:
1 | # CAM中 |
5. (TFA) Frustratingly Simple Few-Shot Object Detection
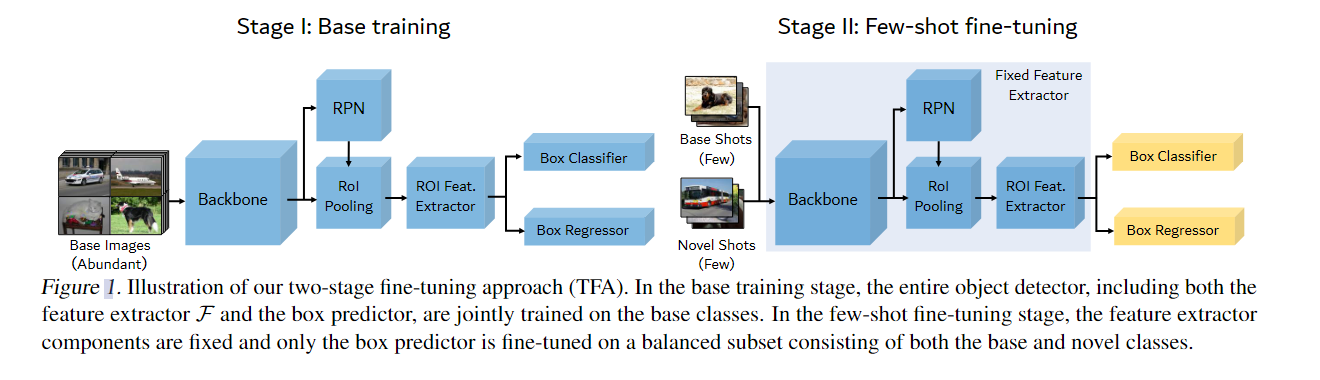
微调方法:
- 使用Faster RCNN作为检测器,第一阶段正常训练
- 在新类上微调时,只微调分类器,前面的固定,并且分类器改为cosine similarity classifier
代表了第个区域建议框和第个类别的相似度
6. (MetaDet) Meta-Learning to Detect Rare Objects
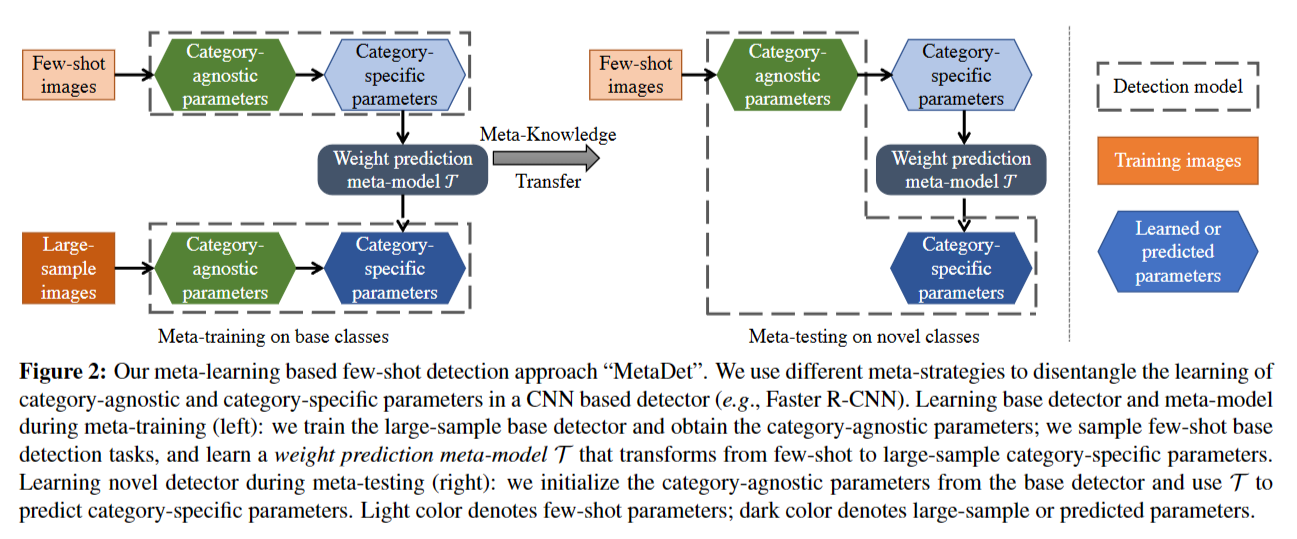
思想:
- 和5.Frustratingly Simple Few-Shot Object Detection 有共同的发现
- 根据CNN的研究,模型分为两部分,1)类别无关(CNN底层) 2)类别相关(CNN顶层)
- 类别无关的部分可以直接迁移到新类上(参数共享),类别相关的部分使用一个元参数预测类别相关部分的模型
- Weight Prediction Meta-Model
- 从大批量数据中学习到的参数为,从k-shot样本中学习到的参数是,mete-model T的任务是:
- ,使用损失函数
7. (CoAttention) One-Shot Object Detection with Co-Attention and Co-Excitation
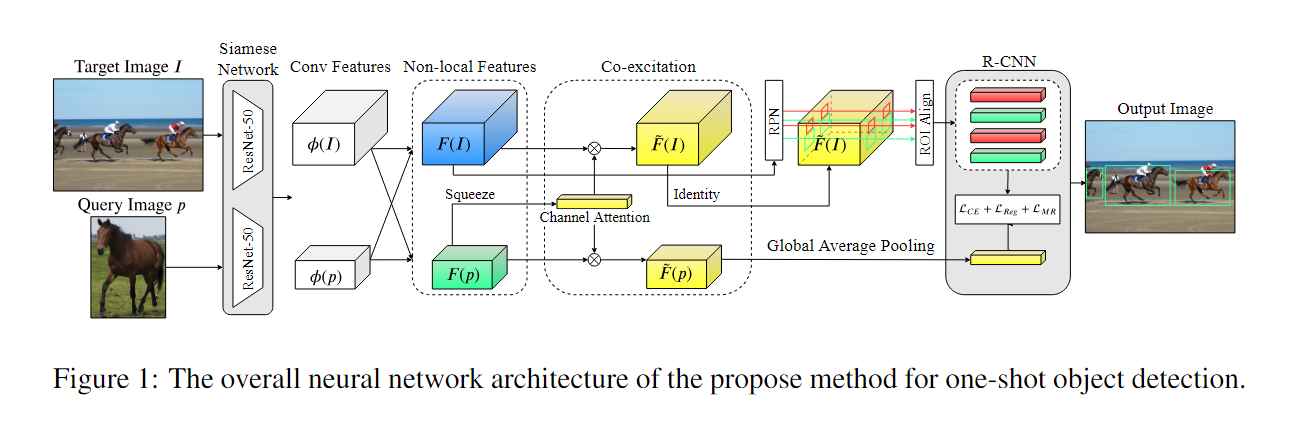
思想:
-
通过非局部操作(每个点的计算都考虑到全图其他点的相似度)来探索每个查询-目标对中体现的共同注意(为了丰富RPN对novel class的提议,与query image提供的类别参考具有外观相似性的RoIs),
$ F(I)=\phi(I) \oplus \psi(I ; p) \in \mathbb{R}^{N \times W_{I} \times H_{I}} \quad for target image, I F(p)=\phi(p) \oplus \psi(p ; I) \in \mathbb{R}^{N \times W_{p} \times H_{p}} \quad for image patch, p ,\phi(I)\psi(I ; p)$代表non-local操作 -
利用Squeeze and co-excitation(SCE模块)自适应地重新加权 N 个通道上的重要性分布来灵活地匹配候选提议(强调那些在评估相似性度量方面起着至关重要的作用的特征通道).
首先对支持特征做全局平均池化,得到一个向量,用这个向量调整支持特征和查询特征的权重. -
候选框排名,将RoI(RPN提供的128个候选框)与支持特征Concat,然后对每个候选框进行分类(分为前景和背景,标签根据与真实框的关系(IoU>0.5)得到).为了与支持特征最相关的候选框排在前面.
关键点:
- 增强RPN对novel class的提议
- 通道注意力
8. (FSDetView) Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild.
Viewpoint Estimation和少样本检测的结合,忽略Viewpoint Estimation,只看Few-Shot Object Detection
思想:
- 一个稍微复杂点的聚合模块,其他和Meta R-CNN类似,Meta RCNN 和Meta Yolo中的聚合:
- 本文提出的聚合:
- ,特征减法衡量图像特征之间的相似性,嵌入本身,没有任何重新加权,也包含相关信息.
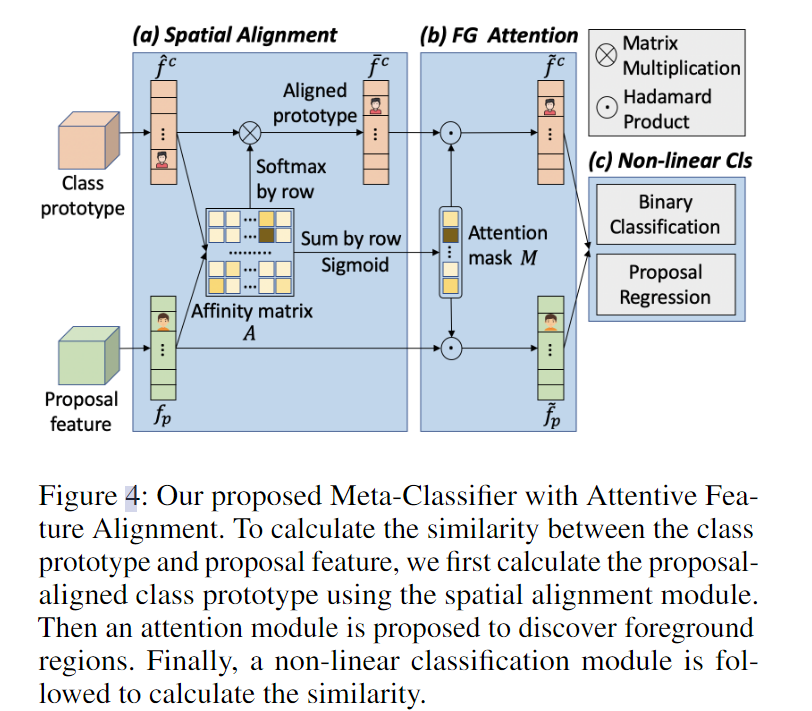
9. (MetaFasterRCNN) Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment.
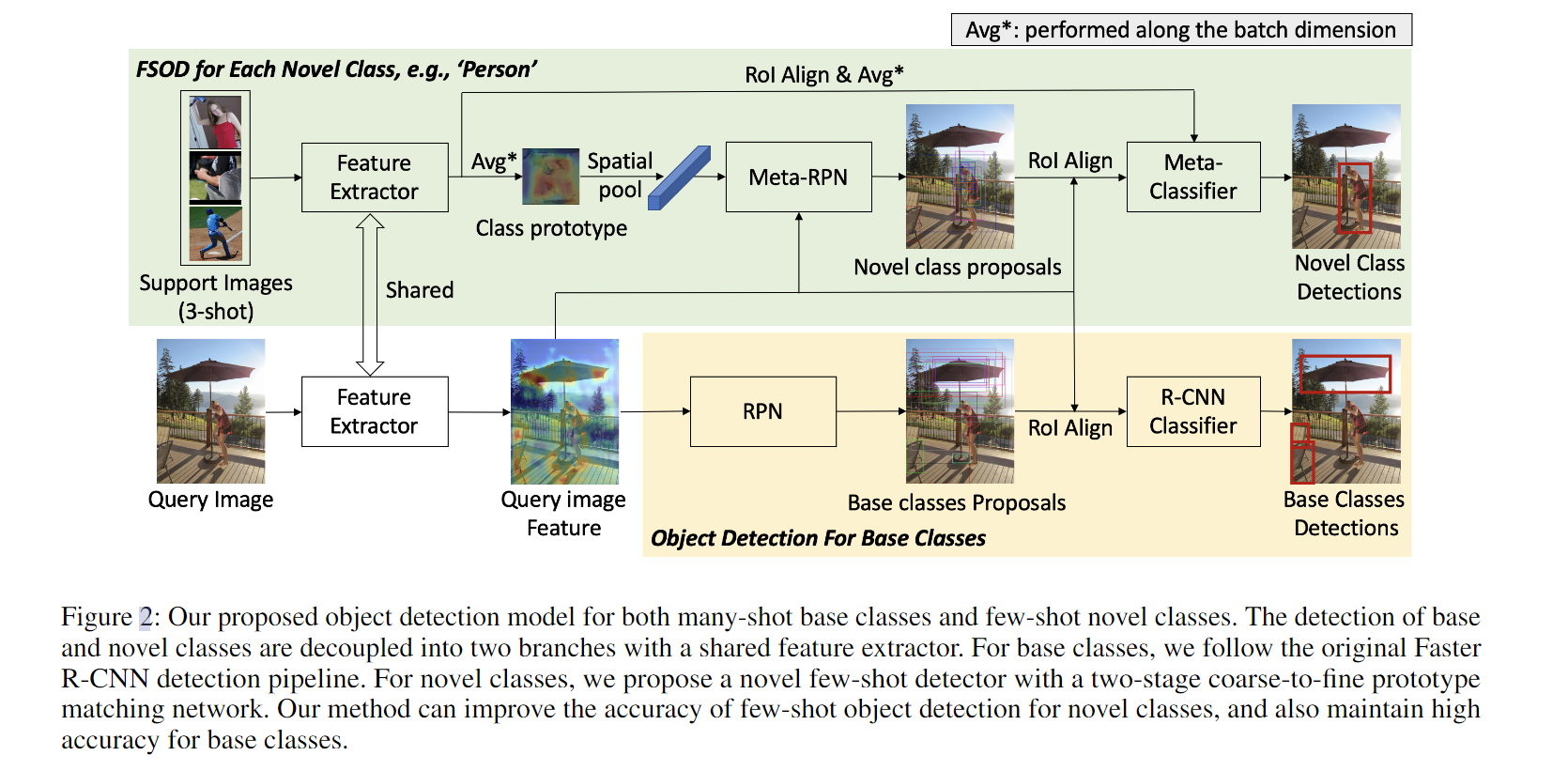
问题:
- RPN对novel class的提议不好
- novel class的候选框和支持特征中的对象位置不对齐
思想:
- 对Base Class训练一个单独的Faster RCNN用来检测
- 提出Meta-RPN module,用于增强RPN对novel class的提议
首先对支持特征对查询特征进行卷积然后生成锚框,对支持特征进行spatial average pool得到和锚框大小一样的特征(多个查询图形取平均),然后送入Meta-RPN module,就是图三中左边上下两个特征图.
Feature Fusion的公式,Based on 8.Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild.
-
使用高分辨率的支持特征来计算和候选框直接的相似度,但是候选框和支持特征中的对象位置不对齐,所以基于注意力的特征对齐方法来解决空间错位问题.
-
(Spatial Alignment)首先通过计算亲和矩阵来建立两个输入特征之间的软对应关系(每个像素点之间的关系,矩阵大小为),然后计算每个像素点之间的相似度:
然后每个空间位置i就通过聚合类原型中所有位置的嵌入来计算:
-
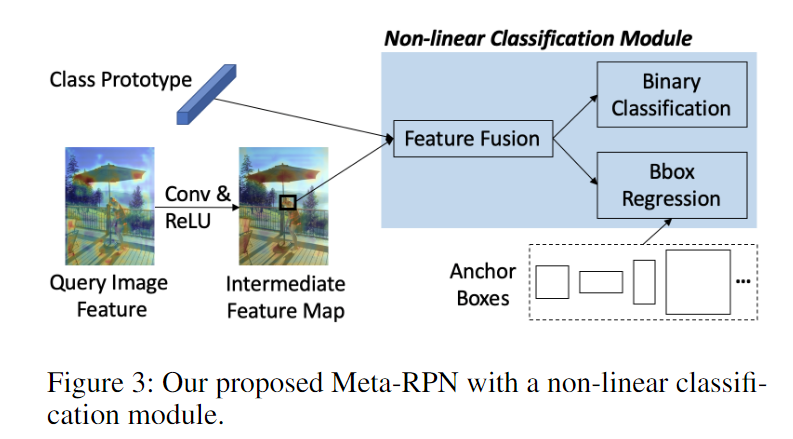
(Foreground Attention Module)生成一个Attention mask来抑制背景,增强前景.候选框中的每个像素i与每个空间位置的相似度:
其中 M 中的较高值表示候选框中的对应位置更类似于对齐原型类的位置,并且更有可能是相同的语义部分。背景区域很难在类原型中找到相似度较高的位置,导致M中的值较低,最后将M和相乘,再通过类似残差连接的一个可学习参数,得到最终的特征: -
(Non-linear Classifier Module)为了衡量最终的候选框和支持类之间的相似性,使用特征融合网络来聚合两个高分辨率的特征,
然后将送入预测类和框的层
训练:
- 使用base class进行元学习,不需要微调就可以应用到novel class上
- 训练完之后,用novel class+base class的数据进行微调(这不作弊吗?)
10. (FSCE) FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
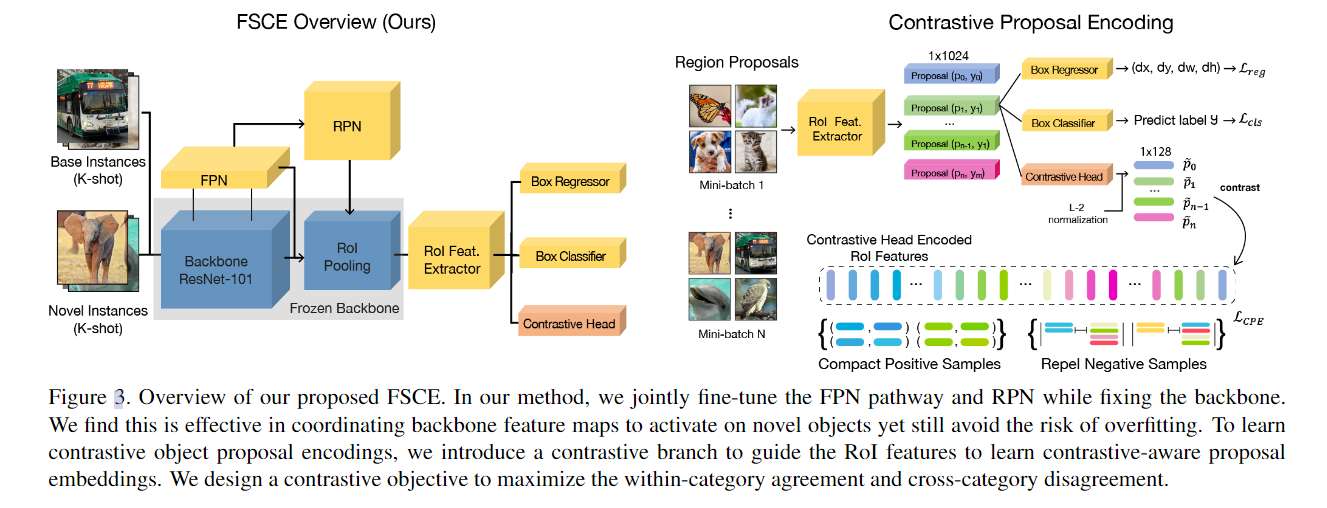
问题:
- transfer learning的方法通常精确度高
- 精确度的退化主要来自将新实例错误分类为易混淆的类,定位基本准确(现有模型并没有学习到一个好的类别特征嵌入)
思想:
- 减小类内方差,增大类间方差,使用对比学习(To learn instance-level discriminative feature representations, contrastive learning has demonstrated its effectiveness in tasks including recognition, identification and the recent successful self-supervised models. )
- RPN推荐的novel class只有base class的四分之一
- 在NMS(非极大值抑制)之后保留的提议数量×2。这样的话,能够为后续提供更多可能包含前景的提议
- 将RoI头中用于计算损失的候选框减少一半,因为一半多的候选框都包含的是背景(提升前景框的比例)
- 对比提议编码( Contrastive Proposal Encoding)
- RoI features因为有Relu激活,部分为0,所以用一个FC层来编码,获取到128维的对比特征
- 使用余弦相似度计算候选框之间的相似度,并优化对比目标使得类间方差大,类内方差小
- Contrastive Proposal Encoding (CPE) Loss
$\mathcal{L}{C P E}=\frac{1}{N} \sum{i=1}^{N} f\left(u_{i}\right) \cdot L_{z_{i}} L_{z_{i}}=\frac{-1}{N_{y_{i}}-1} \sum_{j=1, j \neq i}^{N} \mathbb{I}\left{y_{i}=y_{j}\right} \cdot \log \frac{\exp \left(\tilde{z_{i}} \cdot \tilde{z_{j}} / \tau\right)}{\sum_{k=1}^{N} \mathbb{I}{k \neq i} \cdot \exp \left(\tilde{z{i}} \cdot \tilde{z_{k}} / \tau\right)}z_iy_iu_iN_yf\left(u_{i}\right)z_i\tilde{z_{i}}ij$)为相同类别时,其相似度越高,该损失的值就越小,这将引导相同类别的特征嵌入在学习过程中变得更紧凑,而不同类别的特征嵌入将变得更分散,
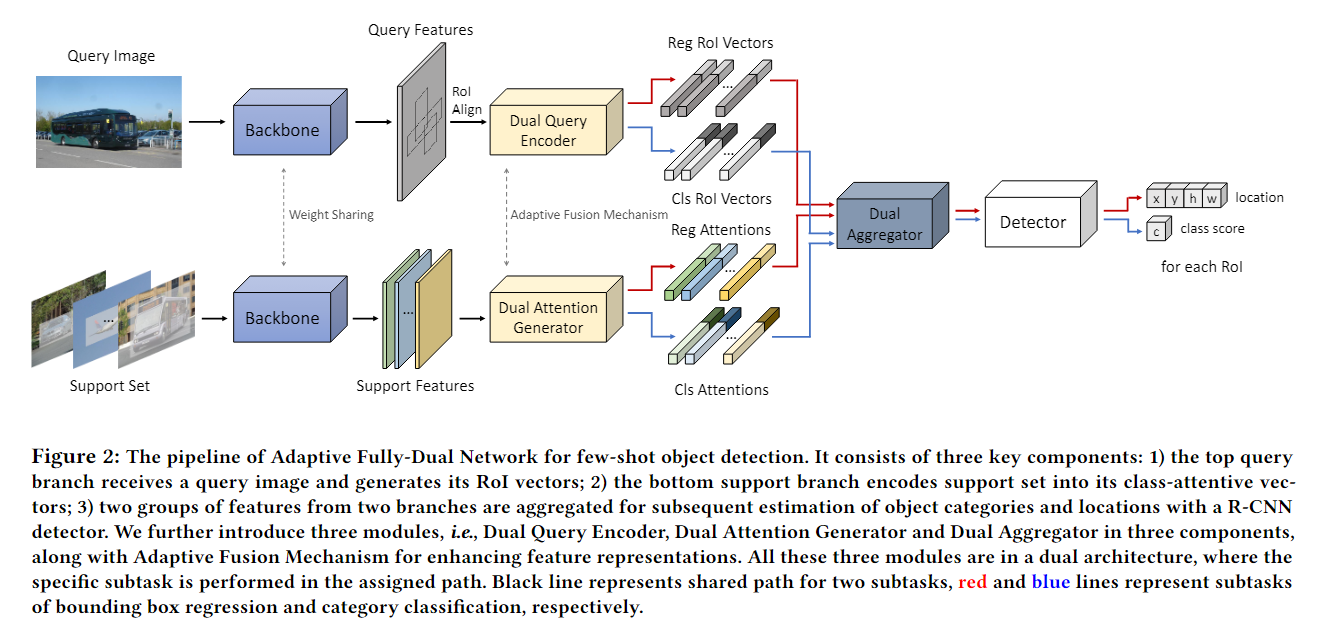
11. (AFDNet) AFD-Net: Adaptive Fully-Dual Network for Few-Shot Object Detection
问题:
- 在目标检测中,分类和定位是完全不同的两个子任务,使用相同的特征进行这两个任务不好
思想:
- 提出了Adaptive Fully-Dual Network(AFD-Net,自适应全双网络),将分类和定位解耦
- 查询图像使用双询问编码(Dual Query Encoder,DQE)输出用于分类和定位的查询他特征
- 支持图像使用双注意力生成(Dual Attention Generator,DAG)输出用于分类和定位的类被注意(支持)特征
- 用于分类和定位的查询特征和支持特征分别送入双聚合器(Dual Aggregator,DA)用于分类和定位
- Dual Attention Generator比Dual Query Encoder多了一个Max Pool来保证支持特征的大小和查询特征的大小一致
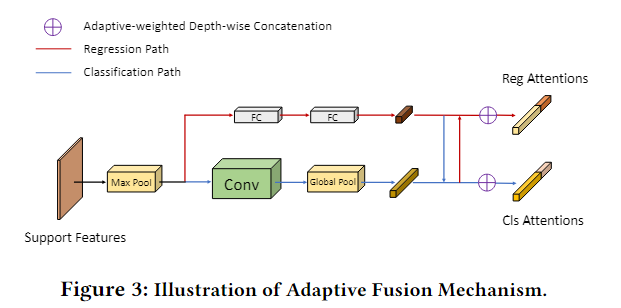
分类分支使用卷积处理,回归任务使用全连接处理,最后各乘一个可学习的权重,concat在一起 - Dual Aggregator的聚合方式和8.(FSDetView) Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild.一样
12. (DeFRCN) DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection
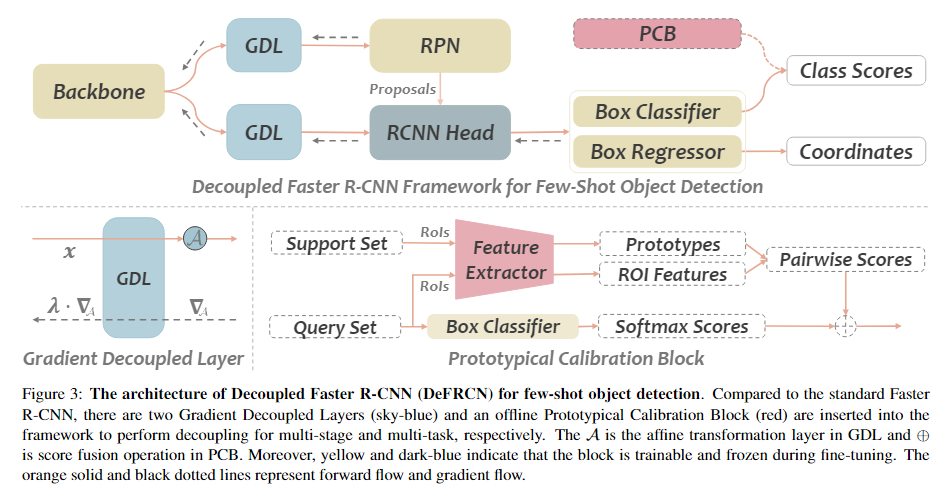
问题:
- multi-stage (RPN vs. RCNN)
- RPN应该是类无关的
- RCNN应该是类相关的
- 但是二者共用一个backbone,梯度会回流到backbone带来冲突
- 通过梯度调整三个模块(backbone,RPN,RCNN)之间的解耦程度来缓解整个模型不被其中一个支配
- multi-task (classification vs. localization).
- 分类任务需要平移不变性,而定位任务对位置敏感
- 在分类分支上使用一个有效的分数校准模块来实现解耦两个任务
思想:
-
在RPN,RCNN和backbone之间引入GDL,使用一个decoupling coefficient 来控制梯度的流动,从而减少不同模块之间的相互影响,
有三种可能,分开讨论 -
PCB由一个预训练模型,一个ROIAlign层和一个分类器组成.首先从支持集中提取特征 ,然后使用RoIAlign与GroundTruth生成MK个实例,然后对k个实例的特征取平均,得到m个类别原型. 然后给定(由检测器得到),利用预测出来的框,使用RoIAlign对齐,得到预测特征,计算预测特征和类原型之间的相似度分数,最后的预测类别得分为:
13. (FCT) Few-Shot Object Detection with Fully Cross-Transformer
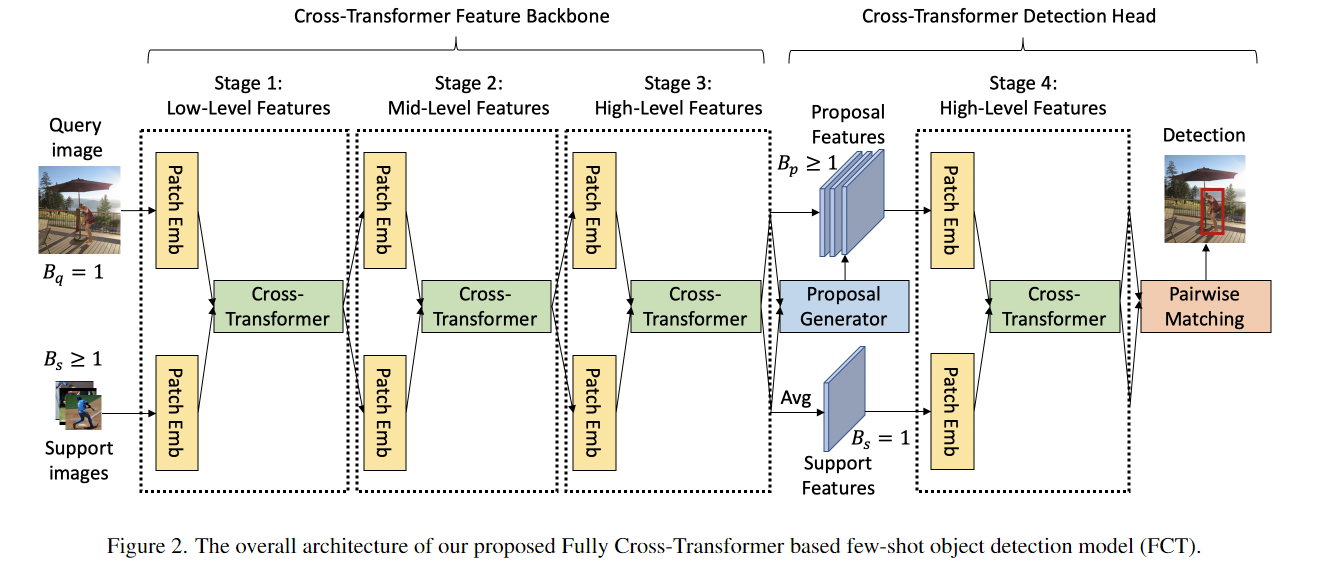
问题:
- 之前的工作,支持分支和查询分支的交互仅限于在检测头,剩余的几百个层的特征都是独立的,
思想:
- backbone中的Cross-Transformer之前
- 在送入之前,把图像分成大小的patches.然后展平扩展通道数为
- 加上位置编码,和批次编码之后(),再经过映射得到KVQ(为了减少计算量,使用了空间缩减)
- The Asymmetric-Batched Cross-Attention,非对称批处理交叉注意
- 支持图像通常大于1,且不固定,这个模块一次计算查询图像与同一类的所有支持图像之间的注意。
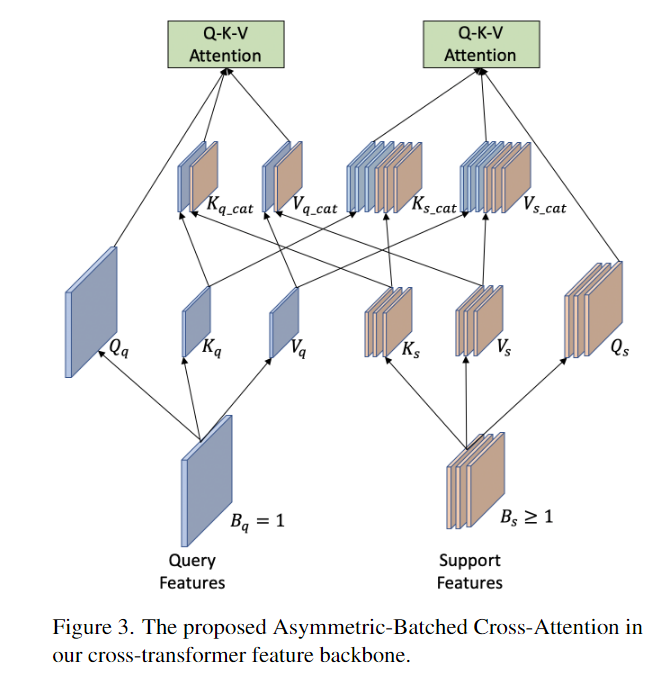
- 对支持图像进行平均池化,使得匹配查询分支的批量大小
- 对查询图像进行重复,使得匹配支持分支的批量大小
- 聚合之后做多头注意力+MLP
- 支持图像通常大于1,且不固定,这个模块一次计算查询图像与同一类的所有支持图像之间的注意。
- The Cross-Transformer Detection Head用于在最终检测之前联合提取建议和支持图像的RoI特征
- 从支持分支提取出100个候选框取平均,只有一个
- 从查询分支提取出100个候选框
- 使用3.Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector中的两两匹配方法进行预测
14. (DeDETR) Decoupled DETR For Few-shot Object Detection
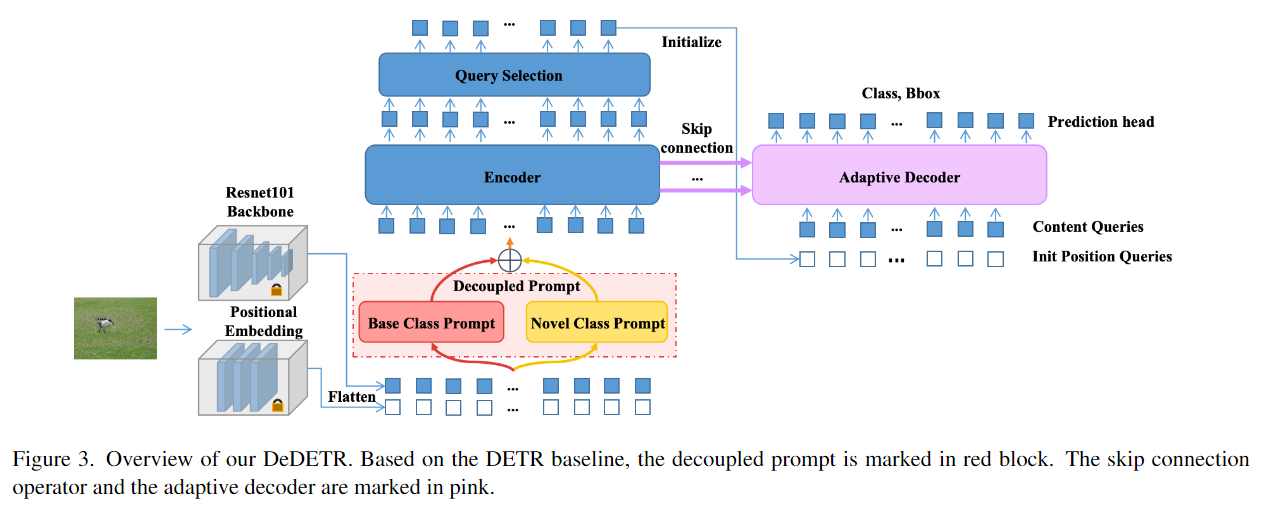
问题:
- FasterRCNN存在定位准确,分类不准确的问题,DETR同样存在(因为极端样本不平衡导致参数优化中数据丰富的类的旧知识占主导地位,这意味着模型总是对数据丰富的类有一定的偏向。)
- 解码器只会使用编码器最后一层的输出作为输入,但是编码器到解码器是一个从浅到深再回到浅的过程,所以浅编码器可能会更好地匹配浅解码器
- 不仅解码器的最后一层能产生正确的预测结果,解码器中间层的输出有时也能产生更好的预测结果。
思想:
-
Decoupled prompts (DePrompt):
- 来自新类的少数样本很难将像 DETR 这样的大型模型推向合适的最优值,因此为新类和基类分配单独的权重集
- 分别为base class 和novel class构建独立的deformable selfattention modules,DePrompt的输出作为编码器的输入,DePrompt的输出由公式决定(w的三种设置)
-
编码器和解码器之间的Skip connection,有两种方式
- 可学习的连接,每一层解码器的输入都有前面所有编码器层的输出乘可学习的权重矩阵得到
- 软连接,每一层解码器的输入都有前面对应的层和最后一层编码器的输出得到
- 可学习的连接,每一层解码器的输入都有前面所有编码器层的输出乘可学习的权重矩阵得到
-
Adaptive decoder selection来解决5个中间层解码器的输出可能比最后一层获得更好的检测结果
- 用可学习的参数动态调整每个层输出的权重
15. (FSRC) Few-shot Object Detection with Refined Contrastive Learning
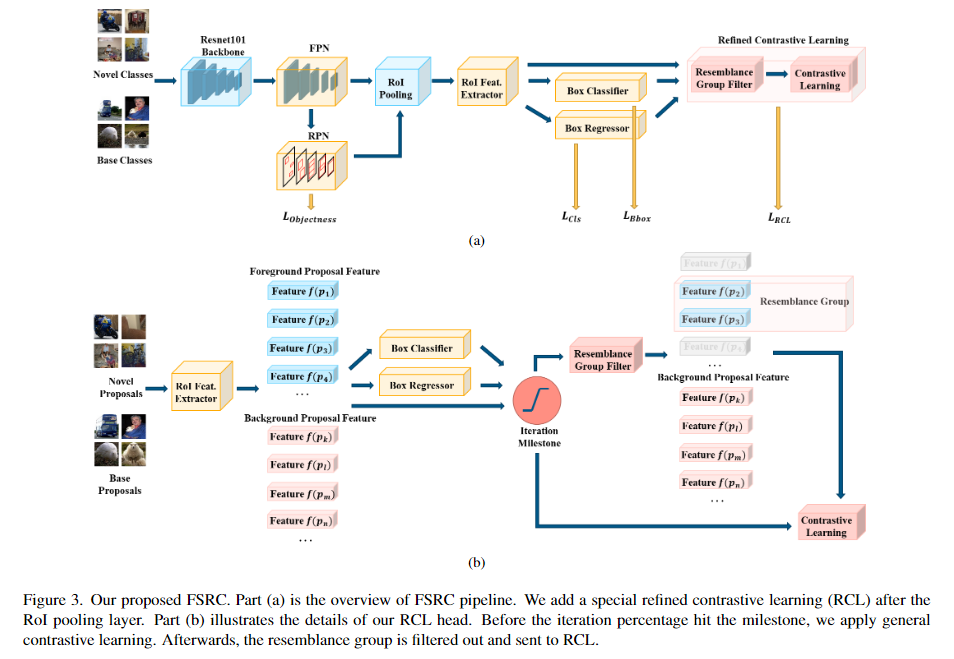
问题:
- 各个类别的检测精度的标准差很大,表明模型对不同类别的检测能力差异很大
思想:
1.在RoiPool前都和FasterRCNN一样,不同的地方在于加上了RCL模块
2. 使用细粒度的对比学习增强学习能力(和10.FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding的区别在于FSCE把所有的类(前景和背景)都考虑进去进行对比),本文先把类间距小的类(相似类)挑出来,然后在这些Resemblance Group中使用对比学习
3. 找到相似类对
- 需要IoU和真实框大于阈值,并且分类错误
- 当一个相似类对出现的次数超过某个阈值后,把这些相似类对中的类都记录下来,作为一个Resemblance Group
- 只有当预测的类别或者真实的类别属于Resemblance Group中的类时,才会进行对比学习
- 这个测量应该在训练过程中使用,因为在刚开始的时候,模型倾向于基类
- 损失函数
.
.
16. (ECEA) ECEA: Extensible Co-Existing Attention for Few-Shot Object Detection
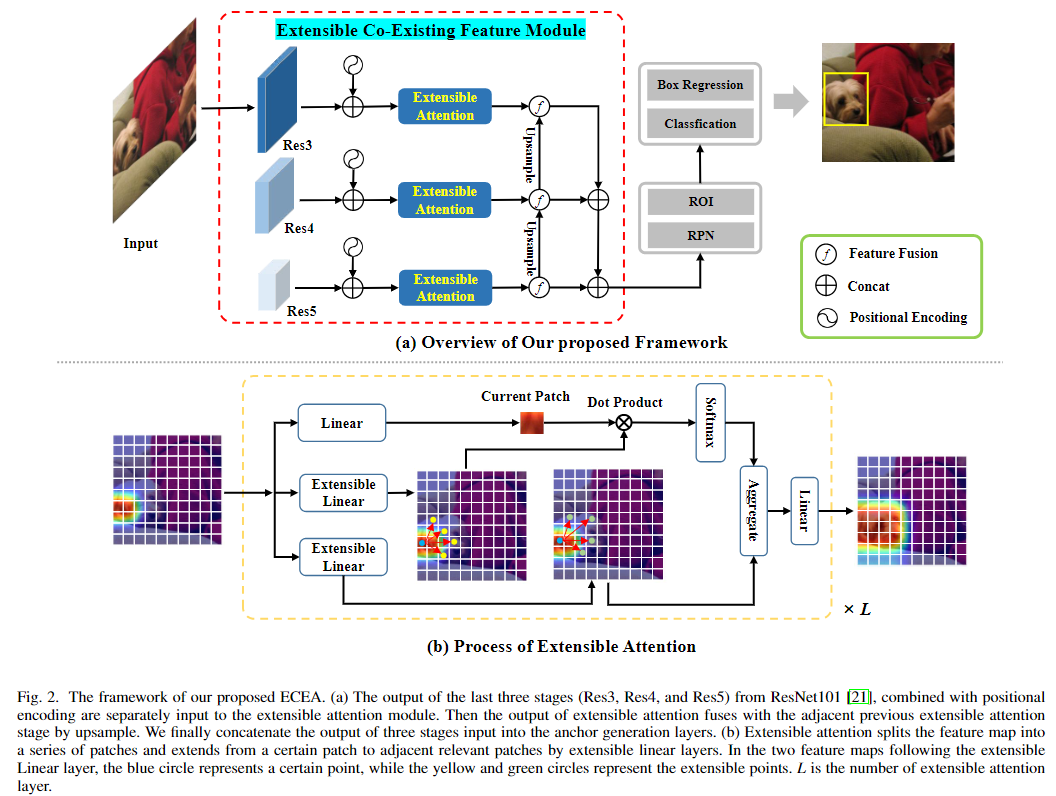
问题:
- 很少考虑到局部到全局的定位(kshot样本可能只能提供novel class的一部分,比如只有狗头,但是要检测出狗身子)
Related Work值得借鉴
思想:
-
提出了一个Extensible Co-Existing Attention(ECEA)模块,使模型能够根据局部部分推断全局对象。本质上,该模型在具有丰富样本的基本阶段不断学习可扩展的能力,并将其转移到新的阶段,可以帮助少镜头模型快速适应将局部区域扩展到共存区域。
-
使用ResNet101的后三层构建多尺度模块经过特征融合之后送到ECEA模块中
-
将特征图划分为一系列patch,表示为,每个patch利用deformable cnn来获得N个extensible regions,…看不懂了
(类似与:一个patch经过得到,然后和其他patch计算相似度,然后和其他patch的相乘,得到最终的特征) -
补充3: Extensible Liner (应该是Deformable 实现)学习到N个可扩展区域的位置和形状,然后和当前的区域进行点积运算,得到相似度分数,然后在和另一个Extensible Liner学习到N个可扩展区域相乘,得到最终的特征(也是的形式,但是中包含了N个相关的扩展区域?)
-
构建了级联的多头多层的Extensible Module,扩展的区域更大,视野更大,更能获得对象的定位
17. (VFA) Few-Shot Object Detection via Variational Feature Aggregation
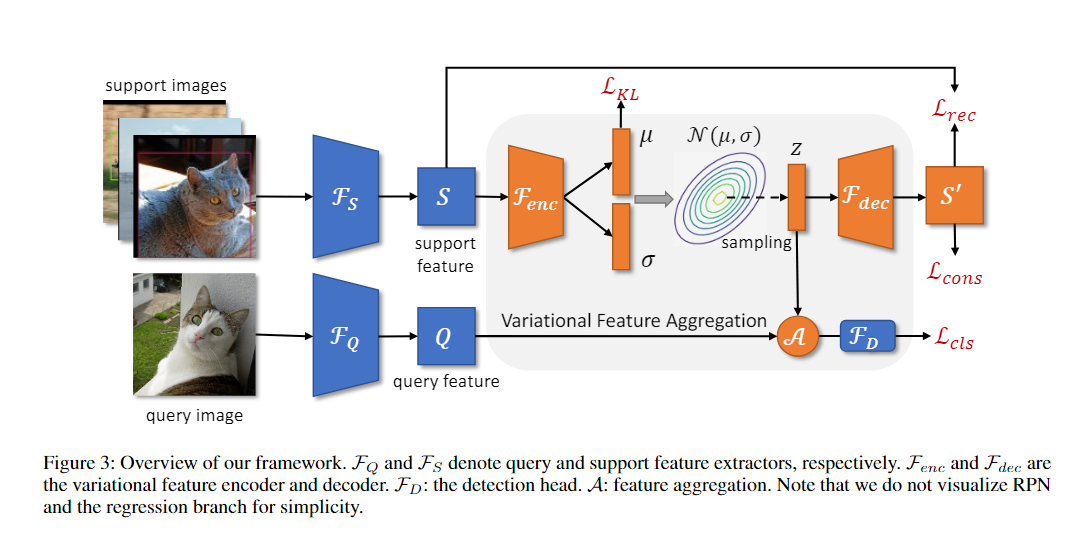
问题:
- class-specific aggregation和class-agnostic aggregation的区别没看懂,没看出来带来什么影响
- 因为novel class的样本太少了,样本间的方差太大,预测结果和样本的质量关系很大
思想:
- 使用class-agnostic aggregation聚合,即在训练时随机挑选一个支持类和查询的RoIfeature进行聚合得到聚合特征
- 使用Variational Feature Aggregation(VFA),先将支持特征转为分布,然后从分布中采样出特征.由于分布不特定于特定的示例,所以方差具有鲁棒性
18. (BCYOLO) Bi-path Combination YOLO for Real-time Few-shot Object Detection
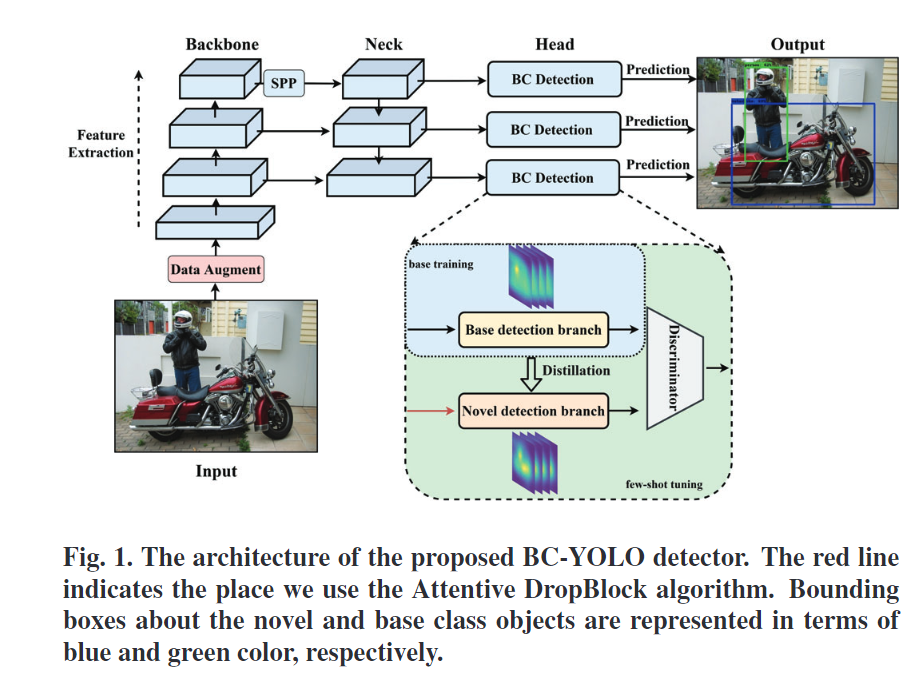
问题:
- 提高模型的检测速度,为了保持较高的推理速度和可接受的检测精度
- 提升 transfer learning的泛化能力
思想:
- 提出了一种双路径组合YOLO(BCYOLO)模型,即base class一个路径,novel class一个路径,novel class的路径由base class蒸馏得到
- 提出一种Attentive DropBlock模块(基于 DropBlock:卷积的dropout可能会根据周围像素点构建出来,因此作用不大,dropblock丢弃的是连续区域),该算法不仅受保持概率和块大小的参数的影响,还受对象语义特征的影响。
19. (CoRPN) Cooperating RPN’s Improve Few-Shot Object Detection
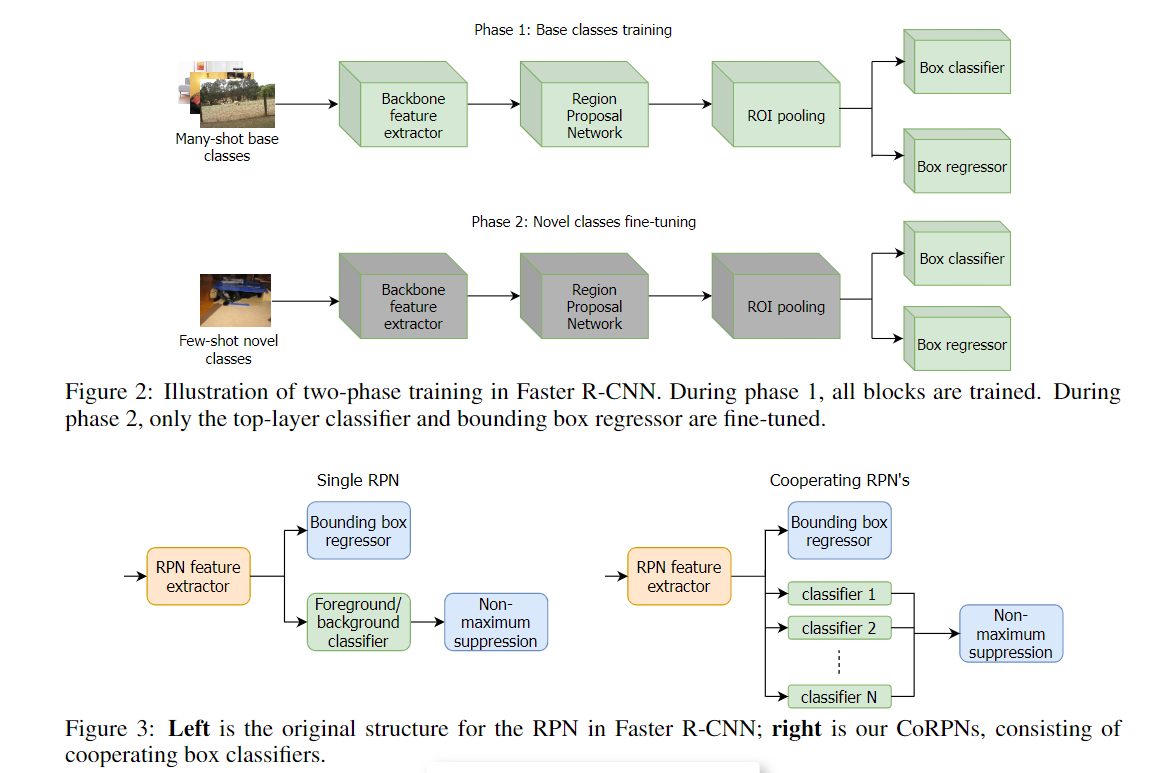
问题:
- RPN对新类的提议不好,RPN 必须尽可能报告尽可能多的高 IOU 框,否则分类器将太弱而无法建模外观出现变化的新类。不能简单地报告大量框来逃避这种影响,因为这样做将需要分类器非常擅长拒绝误报。
思想:
- 训练多个RPN,这些RPN应该是不同的,但是合作的
- 应该选用哪个RPN(不能单单选择分数最高的,其他的没用了):
- 对框i的所有评分取sigmoid,把接近[0,1]的取出来,只有被选择的框才获取到梯度
- 多样性:
- N个RPN和M个锚候选框,构建一个矩阵,最大化矩阵的秩
- 协同(防止有RPN一直拒绝任何前景框):
- ,充当每个 RPN 分配给前景框的概率的下限。如果 RPN 的响应低于 φ,则 RPN 将受到惩罚。
19. ★(DEVit) Detect Every Thing with Few Examples
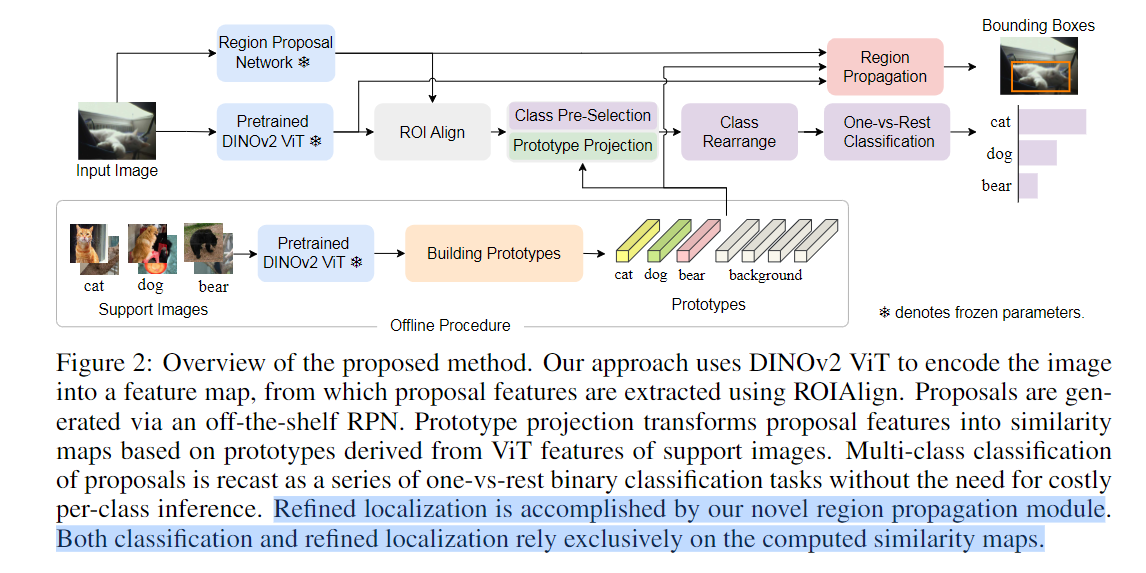
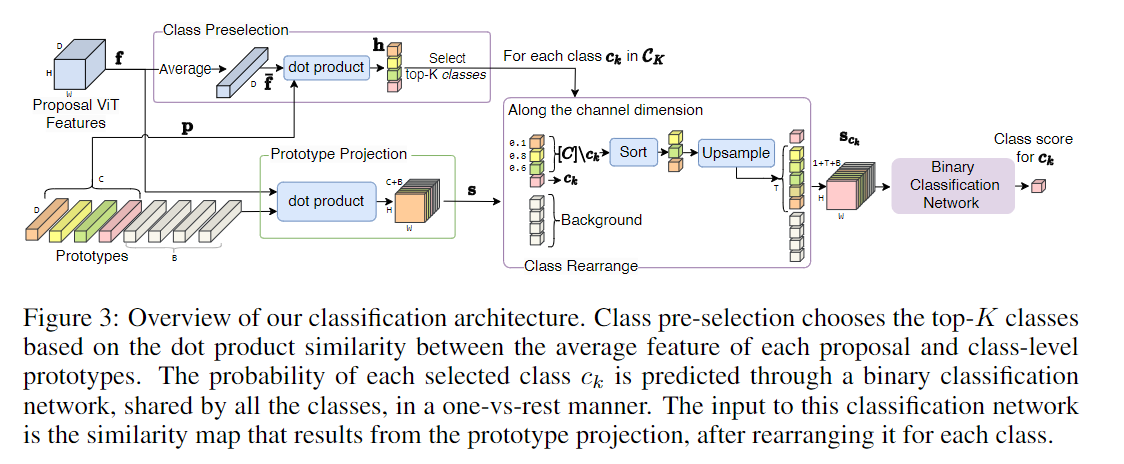

应用
总结
上述的论文对模型的改进基本都是在综述所讲的范围之内
