Zero-shot Object Detection
缺点: 需要结合文本信息,没办法完全根据图片进行检测
综述
A Survey of Vision-Language Pre-Trained Models
视觉语言多模态综述
介绍了视觉语言多模态的1. 特征表示 2. 模态交互 3. 预训练任务 4. 下游任务 5. 方向
2022年之前的VL预训练模型和常用数据集
网页
介绍了Zero-Shot Object Detection的基本概念,以及如何使用Region-CLIP进行Zero-Shot Object Detection
一个样例代码,使用CLIP进行检测
论文
Zero-Shot Detection
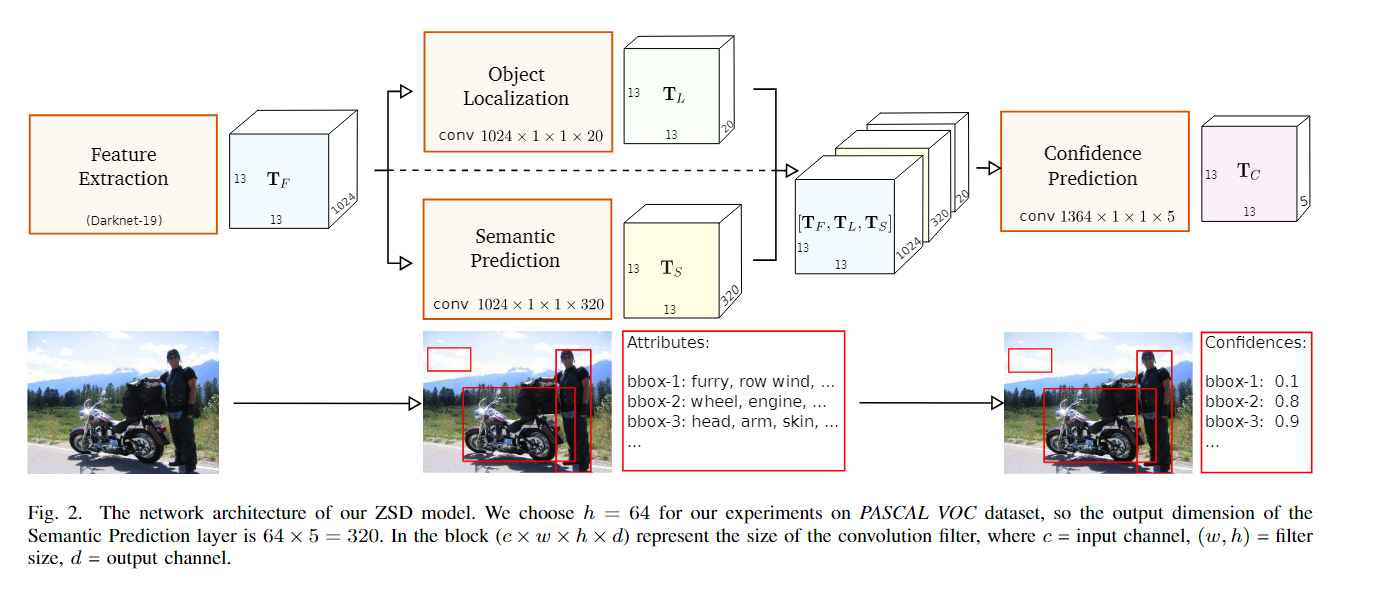
- 利用BackBone抽出来图像的特征
- 在上进行检测,得到目标的位置信息
- 在上进行语义预测,得到目标的文本信息
- 把拼接起来,进行置信度的预测,得到了最终的预测结果(x,y,w,h,cls)
- 损失函数由1)位置损失 2)语义损失 3)置信度损失组成
- 在验证过程中分为Test-Seen,Test-Unseen,Test-Mix三种情况
解决问题:
- RPN可能无法提议出那么多没见过的物体
- 基于YOLOv2,性能强大
- 简单容易理解
Zero-Shot Object Detection
方法:
- 两阶段检测器结构,对区域建议框内的物体抽取出图像特征
- 通过映射将图像特征映射到文本特征空间(通过wordEmbedding得到)
- 在公共空间计算图像特征和文本特征的相似度,得到未见物体的类别
解决问题:
- 将未见物体分为背景的解决
- 使用固定的背景类:在嵌入空间中为背景添加一个固定的向量
- 将多个潜在的类分配给背景对象,不断的将背景框标记为对象反复训练
- 密集采样嵌入空间:数据集中可见类太少了导致公共空间稀疏,未见类的语义和视觉之间无法对齐
- 使用除了未见类之外的额外数据补充训练
Region-CLIP
- 利用RPN从图像中提取出region,抽取出特征
- 利用现有文本解析器,从文本中提取出concept,抽取出特征
- 利用CLIP计算region和concept的相似度,得到region-text的配对
- 利用三个损失函数训练模型
