数据增强、改进Backbone、改进FPN、改进检测头、改进loss、改进后处理
基础网络
R-CNN
1 | # 之前都是人工提取特征,用机器学习分类 |
SPPnet
1 | # 用CNN提取整个图的特征,把候选区域映射到特征图上 |
FPN
1612

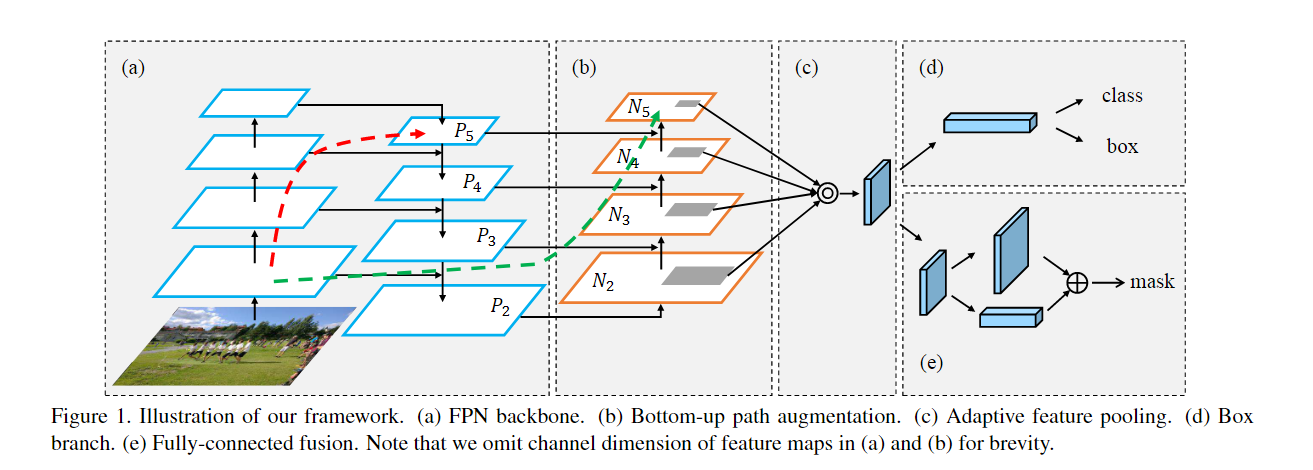
PANet
1803:FPN是自上而下,首次提出了自下而上
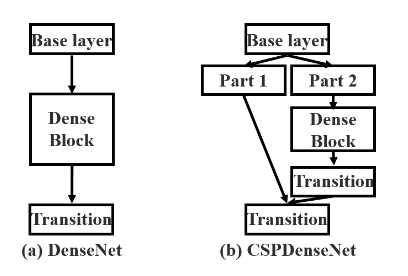
CSPnet
梯度分流,减少计算量和内存
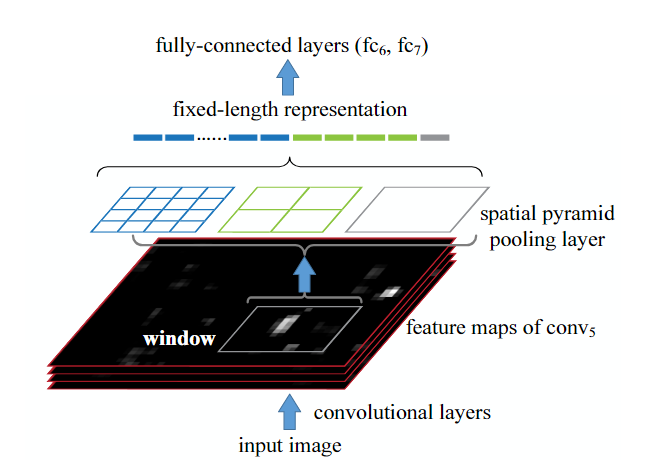
SPP
1406
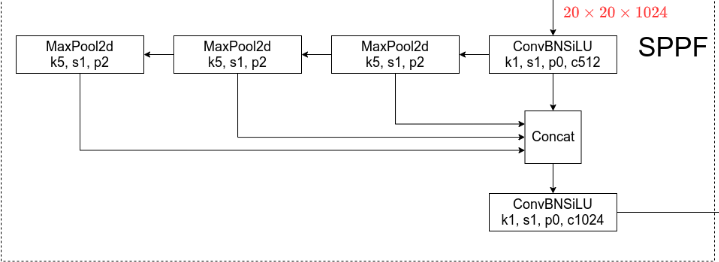
SPPF
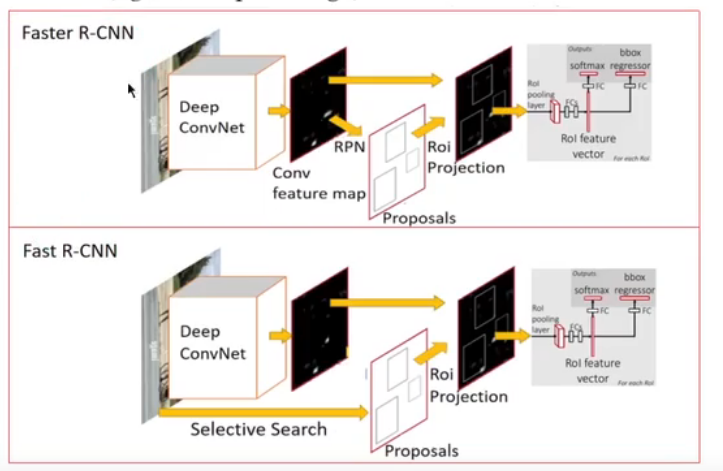
Fast R-CNN
1 | # 针对R-CNN和SPPnet |
Faster R-CNN
1 | # Fast R-CNN还是需要单独的模块生成候选区域投影 |

Mask R-CNN
1 | # Faster R-CNN的RoI Pooling 是直接取整,会导致实例偏移,对于像素级 不可取 |
论文
Analysis of Object Detection Performance Based on Faster RCNN
基于Faster R-CNN的目标检测性能分析
介绍了R-CNN->Fast R-CNN-> Faster R-CNN的变化过程
Faster R-CNN的大概结构
对比三个模型在不同数据集上的效果
End-to-End Object Detection with Transformers
里程碑:端到端的方法,不用非极大值抑制
变成集合预测问题
CNN抽取特征->送入Transformer学习全局特征->输出100个框->二分图loss匹配真实框->计算loss
问题:小目标,训练epoch长
EfficientDet: Scalable and Efficient Object Detection
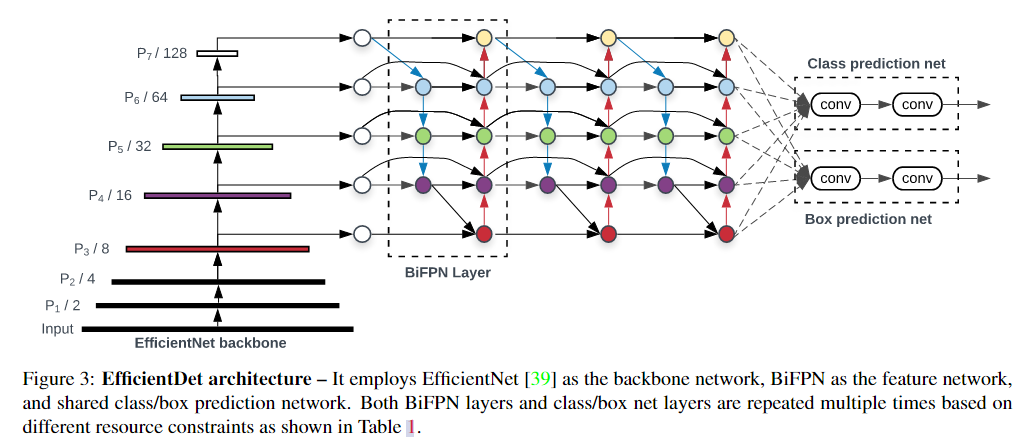
新的结构,多层特征融合
Deformable DETR: Deformable Transformers for End-to-End Object Detection
解决DETR的两个问题

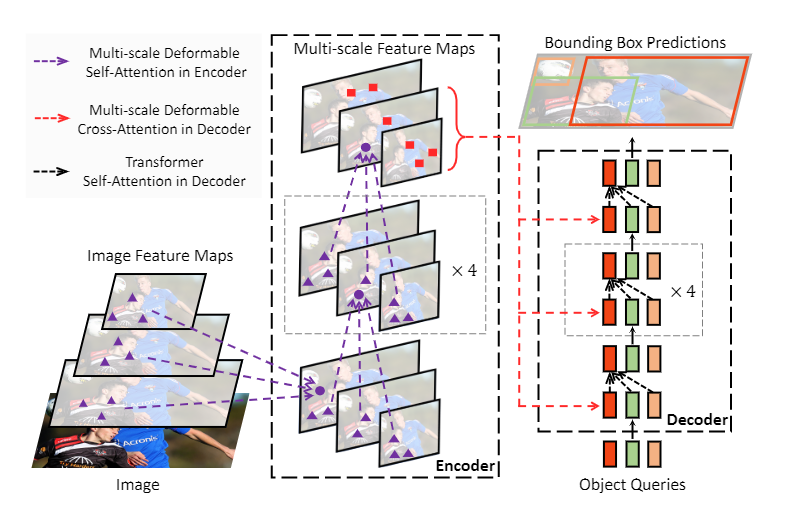
1 | 1.不用TRansformer原有的自注意力,改为可变注意力(可变卷积变来的) |
★Deep learning-based waste detection in natural and urban environments
传统图像分类网络:ResNet,DenseNet,EfficientNet,EfficientNet-B2,EfficientNetv2
经典目标检测网络:R-CNN,Fast R-CNN ,Faster R-CNN,SSD,Yolo,DETR,Deformable DETR,EfficientDet
垃圾数据集
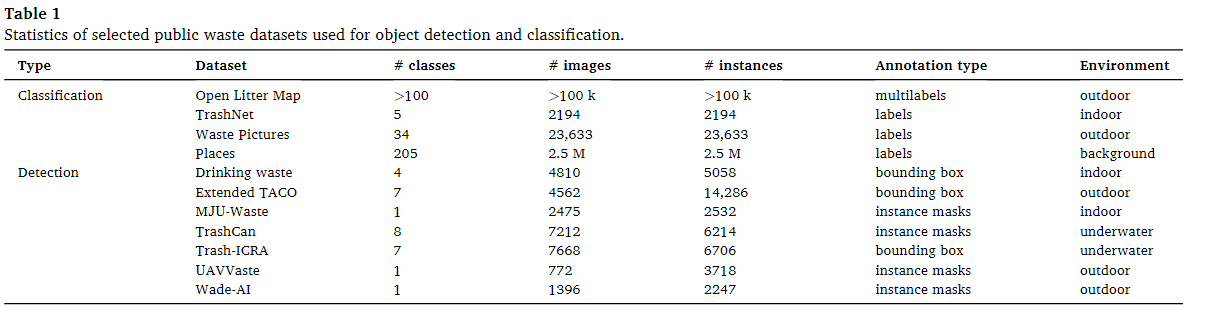
对所有数据集进行处理
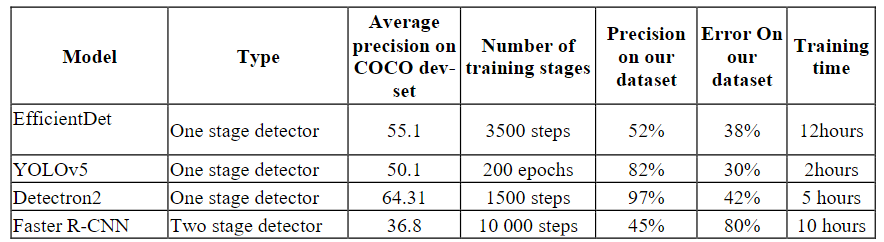
对比模型:Efficentdet, DETR和Mask RCNN,发现Efficentdet能产生最高的mAP
一个目标检测网络EfficientDet-D2,一个图像分类网络EfficientNet-B2
训练步骤:分开训练,先训练目标检测网络,再训练图像分类网络
问题:小目标,推理时间
Garbage object detection method based on improved Faster R-CNN
对Faster R-CNN进行了两点改进:
1.基础网络从VGG16改成了ResNet50
2.增加了FPN特征金字塔
3.将原本的ROI改成ROI Align(Mask R-CNN)
4.修改了RPN结构参数
基于改进 Faster R⁃CNN 的垃圾检测与分类方法
1 | # 把Faster R-CNN 的网络换成了ResNet50 |
Object detection for autonomous trash and litter collection(毕业论文)
针对垃圾收集机器人,管道方法:从数据收集到预测出结果的一系列
- 介绍:在机器人上部署最先进的目标检测模型
- 背景:深度学习(MLP,CNN,YOLO),目标检测,垃圾检测数据集
- 管道方法组成(收集,预处理,增强,训练,验证)
- 自己的管道定义与实现(tile数据增强方法,光强归一化,不同模型)
- 结果与分析
- Future work
1 | 1. 根据数据集中物体大小不同使用不同模型,参数 |
Tiny Object Detection based on YOLOv5
1 | 1. 生成4幅特征图像进行融合 |
YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles
在自动驾驶领域,对小物体检测和检测速度要求很高
很多模型没有修改模型的架构,修改的不痛不痒
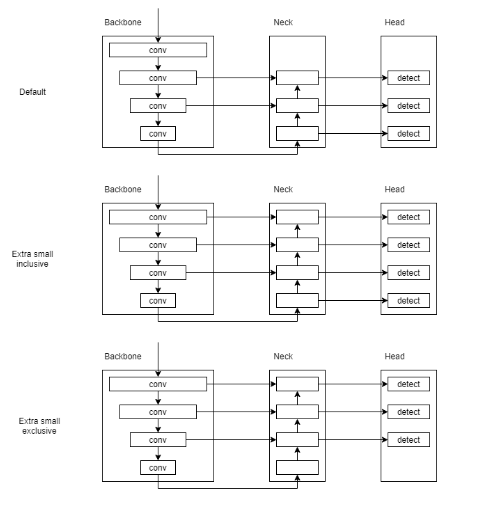
1 | 修改: |
Accuracy and Efficiency Comparison of Object Detection Open-Source Models
1 | 自己构建的杂草检测数据集,使用多种数据增强方法 |
The Object Detection of Underwater Garbage with an Improved YOLOv5 Algorithm
1 | 使用K-means对anchor进行聚类,产生九个新的框大小 |
An Irregularly Dropped Garbage Detection Method Based on Improved YOLOv5s
1 | CBAM 注意力模块 |
Towards Lightweight Neural Networks for Garbage Object Detection
1 | Yolov3 |
Real-Time Garbage Object Detection With Data Augmentation and Feature Fusion Using SUAV Low-Altitude Remote Sensing Images
1 | 修改Yolov4 |
Yolov5
Yolox
Yolov3
1 | 提出了Darknet53 |
Yolov4
1 | 针对input,backbone,neck,head选择不同的结构 |
Yolov5
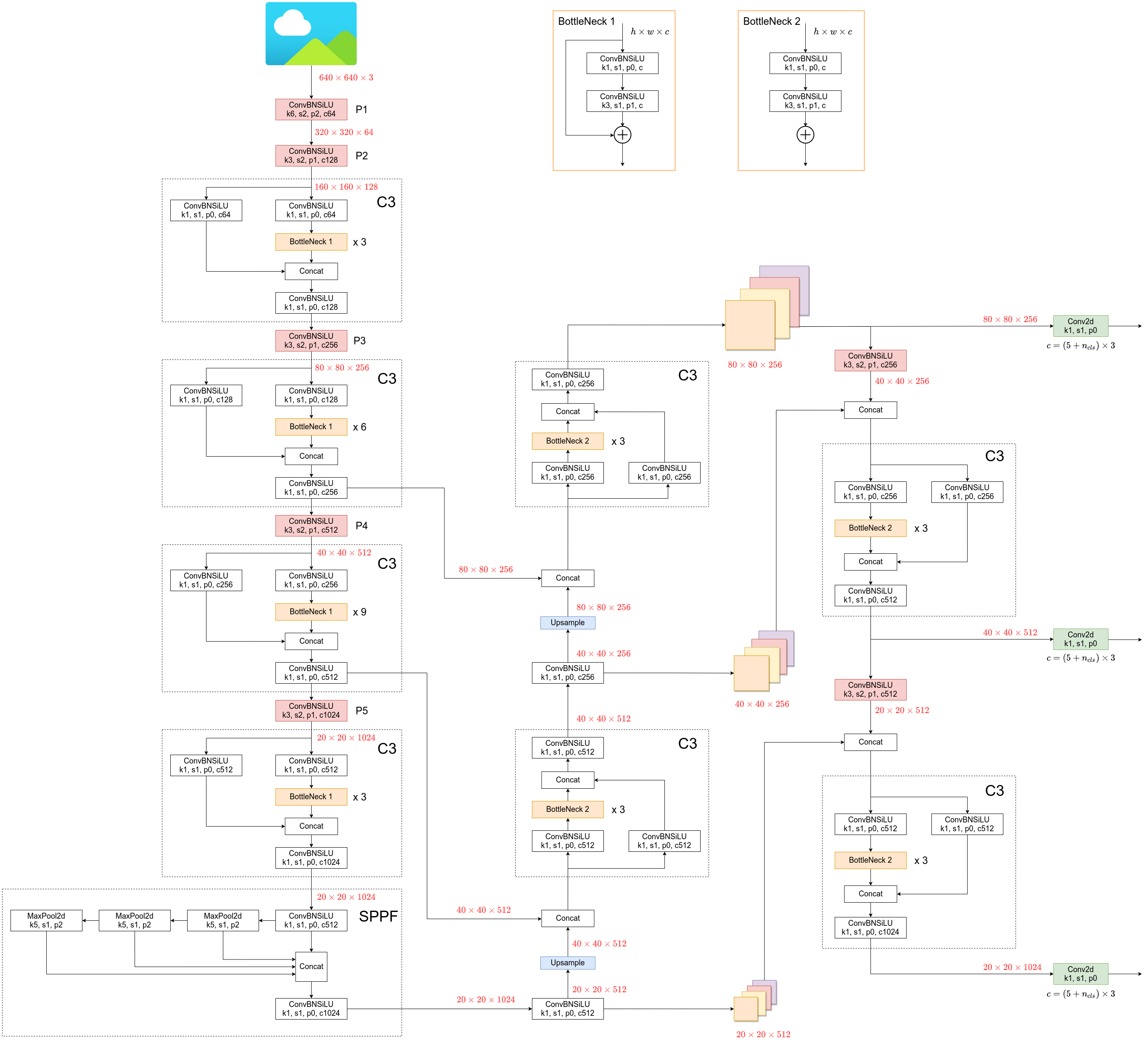
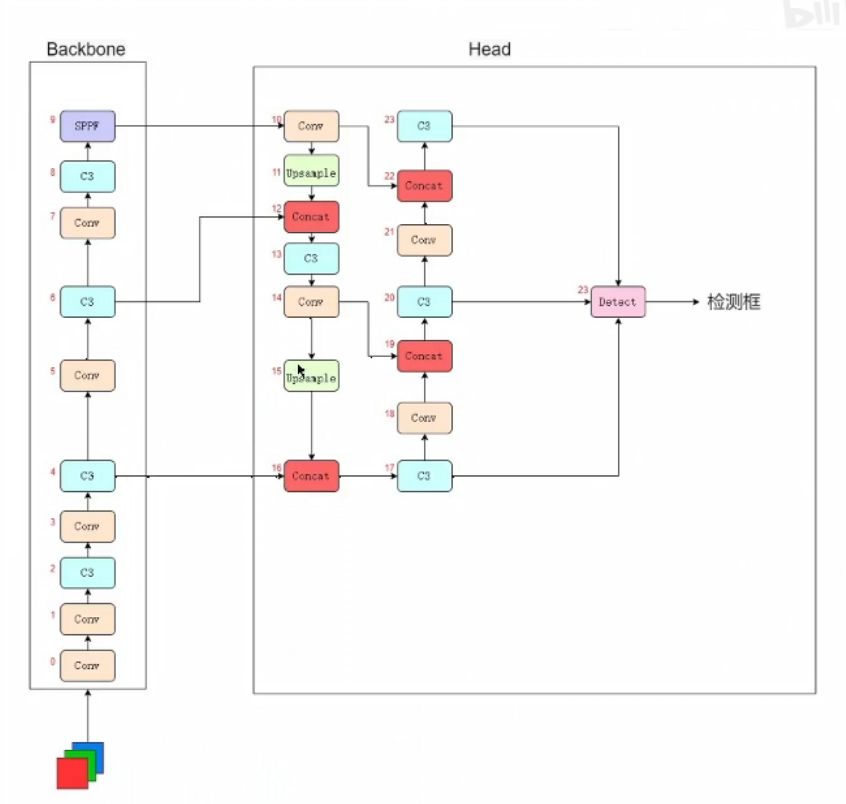
1 |
|
开源复现
FasterR-CNN
1 | 1. 下载到Google Colab |
EfficientDet
1 | # 运行环境Google Colab |
Deformable-DETR
1 | # 运行环境Google Colab |
YOLOv5
1 | # 运行环境Google Colab |
YOLOv8
1 | # 运行环境Google Colab |
