1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import socket'''服务器端''' from socket import socket, SOCK_STREAM, AF_INETfrom base64 import b64encodefrom json import dumpsfrom threading import Threaddef main (): class FileTransferHandler (Thread ): def __init__ (self, cclient ): super ().__init__() self.cclient = cclient def run (self ): my_dict = {} my_dict['filename' ] = 'guido.jpg' my_dict['filedata' ] = 'data' json_str = dumps(my_dict) self.cclient.send(json_str.encode('utf-8' )) self.cclient.close() server = socket() server.bind(('localhost' , 5566 )) server.listen(512 ) print ('服务器启动开始监听...' ) while True : client, addr = server.accept() FileTransferHandler(client).start() if __name__ == '__main__' : main() '''客户端''' from socket import socketfrom json import loadsfrom base64 import b64decodedef main (): client = socket() client.connect(('localhost' , 5566 )) in_data = bytes () data = client.recv(1024 ) while data: in_data += data data = client.recv(1024 ) my_dict = loads(in_data.decode('utf-8' )) print (my_dict) print ('图片已保存.' ) if __name__ == '__main__' : main()
1 2 3 from urllib import parase
1 2 3 4 from urllib import request
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from urllib import robotparserfrom urllib import parsefrom urllib import robotparserAGENT_NAME = 'Googlebot' URL_BASE = 'https://zhuanlan.zhihu.com/' parser = robotparser.RobotFileParser() parser.set_url(parse.urljoin(URL_BASE, 'robots.txt' )) parser.read() PATHS = [ '/' , '/search-special' , '/login' , '/s' , ] for path in PATHS: print ('{!r:>6} : {}' .format ( parser.can_fetch(AGENT_NAME, path), path)) url = parse.urljoin(URL_BASE, path) print ('{!r:>6} : {}' .format ( parser.can_fetch(AGENT_NAME, url), url)) print ()
True : /
True : https://zhuanlan.zhihu.com/
False : /search-special
False : https://zhuanlan.zhihu.com/search-special
False : /login
False : https://zhuanlan.zhihu.com/login
True : /s
True : https://zhuanlan.zhihu.com/s
1 2 3 4 5 6 7 8 9 10 11 12 13 import base64initial_data='Copyright (c) 2008 Doug Hellmann All rights reserved.' print (f'initial_data:{initial_data} ' )byte_string = initial_data.encode('utf-8' ) encoded_data = base64.b64encode(byte_string) print (f'base64 data:{encoded_data} ' )encoded_data = b'VGhpcyBpcyB0aGUgZGF0YSwgaW4gdGhlIGNsZWFyLg==' decoded_data = base64.b64decode(encoded_data) print ('Encoded :' , encoded_data)print ('Decoded :' , decoded_data)
initial_data:Copyright (c) 2008 Doug Hellmann All rights reserved.
base64 data:b'Q29weXJpZ2h0IChjKSAyMDA4IERvdWcgSGVsbG1hbm4gQWxsIHJpZ2h0cyByZXNlcnZlZC4='
Encoded : b'VGhpcyBpcyB0aGUgZGF0YSwgaW4gdGhlIGNsZWFyLg=='
Decoded : b'This is the data, in the clear.'
1 2 3 from http import server
1 2 3 from http import cookie
1 2 3 4 5 6 import webbrowserwebbrowser.open_new_tab( 'https://docs.python.org/3/library/webbrowser.html' )
True
1 2 3 4 import uuidprint (uuid.getnode())print (uuid.uuid1())
4943745048992
1e4a5d1c-cc80-11ed-8e72-047f0e2ae1a0
1 2 3 4 5 6 7 8 9 10 import jsonjson.load() json.dump() json.loads() json.dumps()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from smtplib import SMTP,SMTP_SSLfrom email.header import Headerfrom email.mime.text import MIMETextfrom email.mime.image import MIMEImagefrom email.mime.multipart import MIMEMultipartdef main (): message = MIMEMultipart() text_content = MIMEText('附件中有本月数据请查收' , 'plain' , 'utf-8' ) message['From' ] = Header('gladdduck' , 'utf-8' ) message['To' ] = Header('亚哥' , 'utf-8' ) message['Subject' ] = Header('本月数据' , 'utf-8' ) message.attach(text_content) with open ('words.txt' , 'rb' ) as f: txt = MIMEText(f.read(), 'base64' , 'utf-8' ) txt['Content-Type' ] = 'text/plain' txt['Content-Disposition' ] = 'attachment; filename=hello.txt' message.attach(txt) smtper = SMTP_SSL('smtp.qq.com' ) sender = '703214452@qq.com' receivers = ['syxue@stu.suda.edu.cn' ] smtper.login(sender, '*****' ) smtper.sendmail(sender, receivers, message.as_string()) smtper.quit() print ('发送完成!' ) if __name__ == '__main__' : main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import argparseparser = argparse.ArgumentParser(description='test' ) parser.add_argument("echo" ) parser.add_argument("-v" , "--verbose" ) ''' add_argument()参数 action:默认是store,存储参数 store_const:表示只能赋值为const append:把参数存储成列表 append_const:把const的值存储为列表 count:统计参数出现的次数 store_true/store_false:保存布尔值,出现就是true or false default:默认值 type:参数类型 choice:只能从里面选 required:可以省略 (仅针对可选参数)。 help:打印的时候的帮助信息 dest:解析后的参数名称 nargs:表示后面要跟几个参数 group=parser.add_mutually_exclusive_group()互斥选项, ''' parser.parse_args()
1 2 3 4 import getpassp=getpass.getpass(prompt='输入密码' ) print (p,p)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import configparser''' [DEFAULT] serveraliveinterval = 45 compression = yes compressionlevel = 9 [bitbucket] user = kk [topsecrect] port = 22 ''' import configparserconfig = configparser.ConfigParser() config.read('example.ini' ) for section_name in config.sections(): print ('Section:' , section_name) print (' Options:' , config.options(section_name)) for name, value in config.items(section_name): print (' {} = {}' .format (name, value)) print () config.add_section('bug_tracker' ) config.set ('bug_tracker' , 'url' , 'http://localhost:8080/bugs' ) config.set ('bug_tracker' , 'username' , 'dhellmann' ) config.set ('bug_tracker' , 'password' , 'secret' ) config.remove_option('bug_tracker' , 'password' ) config.remove_section('wiki' )
1 2 3 4 5 6 7 8 9 10 11 12 import logginglogging.basicConfig(level=logging.WARNING) logger1 = logging.getLogger('package1.module1' ) logger2 = logging.getLogger('package2.module2' ) logger1.warning('This message comes from one module' ) logger2.warning('This comes from another module' )
WARNING:package1.module1:This message comes from one module
WARNING:package2.module2:This comes from another module
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import logginglogging.basicConfig(format ='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s' , level=logging.DEBUG, ) logging.debug('debug 信息' ) logging.info('info 信息' ) logging.warning('warning 信息' ) logging.error('error 信息' ) logging.critical('critial 信息' ) ''' 级别 数值 CRITICAL 50 ERROR 40 WARNING 30 INFO 20 DEBUG 10 NOTSET 0 '''
2023-03-28 21:44:07,434 - C:\Users\22627\AppData\Local\Temp\ipykernel_2380\2094327826.py[line:8] - DEBUG: debug 信息
2023-03-28 21:44:07,436 - C:\Users\22627\AppData\Local\Temp\ipykernel_2380\2094327826.py[line:9] - INFO: info 信息
2023-03-28 21:44:07,438 - C:\Users\22627\AppData\Local\Temp\ipykernel_2380\2094327826.py[line:10] - WARNING: warning 信息
2023-03-28 21:44:07,440 - C:\Users\22627\AppData\Local\Temp\ipykernel_2380\2094327826.py[line:11] - ERROR: error 信息
2023-03-28 21:44:07,443 - C:\Users\22627\AppData\Local\Temp\ipykernel_2380\2094327826.py[line:12] - CRITICAL: critial 信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import globimport loggingimport logging.handlersLOG_FILENAME = 'logging_rotatingfile_example.out' my_logger = logging.getLogger('MyLogger' ) my_logger.setLevel(logging.DEBUG) handler = logging.handlers.RotatingFileHandler( LOG_FILENAME, maxBytes=20 , backupCount=5 , ) my_logger.addHandler(handler) for i in range (20 ): my_logger.debug('i = %d' % i) logfiles = glob.glob('%s*' % LOG_FILENAME) for filename in sorted (logfiles): print (filename)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import atexitdef my_cleanup (name ): print ('my_cleanup({})' .format (name)) atexit.register(my_cleanup, 'first' ) atexit.register(my_cleanup, 'second' ) atexit.register(my_cleanup, 'third' ) @atexit.register def all_done (): print ('all_done()' ) print ('starting main program' )
starting main program
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import schedimport schedimport timescheduler = sched.scheduler(time.time, time.sleep) def long_event (name ): print ('BEGIN EVENT :' , time.ctime(time.time()), name) time.sleep(2 ) print ('FINISH EVENT:' , time.ctime(time.time()), name) print ('START:' , time.ctime(time.time()))scheduler.enter(2 , 1 , long_event, ('first' ,)) scheduler.enter(3 , 1 , long_event, ('second' ,)) scheduler.run()
START: Tue Mar 28 21:57:03 2023
BEGIN EVENT : Tue Mar 28 21:57:05 2023 first
FINISH EVENT: Tue Mar 28 21:57:07 2023 first
BEGIN EVENT : Tue Mar 28 21:57:07 2023 second
FINISH EVENT: Tue Mar 28 21:57:09 2023 second
1 2 3 4 5 6 7 8 9 price=0 age=int (input ()) if age<12 : price=0 elif age<=65 : price=40 elif age>65 : price=20 print (f'Your price is {price} yuan' )
Your price is 40 yuan
1 2 3 4 import pydocimport atexitpydoc.doc(atexit)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import doctestdef my_function (a, b ): """Returns a * b. Works with numbers: >>> my_function(2, 3) 6 and strings: >>> my_function('a', 3) 'aaa' # 忽略可能会变化的部分 >>> unpredictable(MyClass()) #doctest: +ELLIPSIS [<doctest_ellipsis.MyClass object at 0x...>] """ return a * b if __name__=="__main__" : doctest.testmod()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import unittestclass SimplisticTest (unittest.TestCase): def test (self ): a = 'a' b = 'a' self.assertEqual(a, b) self.assertFalse() self.assertTrue() self.assertNotEqual() self.assertNotEqual()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import tracedef recurse (level ): print ('recurse({})' .format (level)) if level: recurse(level - 1 ) def not_called (): print ('This function is never called.' ) def main (): print ('This is the main program.' ) recurse(2 ) tracer = trace.Trace(count=False , trace=True ) tracer.run('recurse(2)' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import profileimport pstatsdef fib (n ): if n == 0 : return 0 elif n == 1 : return 1 else : return fib(n - 1 ) + fib(n - 2 ) def fib_seq (n ): seq = [] if n > 0 : seq.extend(fib_seq(n - 1 )) seq.append(fib(n)) return seq profile.runctx( 'print(fib_seq(n)); print()' , globals (), {'n' : 20 }, )
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765]
57409 function calls (119 primitive calls) in 0.156 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
21/1 0.000 0.000 0.156 0.156 1066040024.py:12(fib_seq)
57291/21 0.156 0.000 0.156 0.007 1066040024.py:4(fib)
4 0.000 0.000 0.000 0.000 :0(acquire)
25 0.000 0.000 0.000 0.000 :0(append)
1 0.000 0.000 0.156 0.156 :0(exec)
20 0.000 0.000 0.000 0.000 :0(extend)
3 0.000 0.000 0.000 0.000 :0(getpid)
3 0.000 0.000 0.000 0.000 :0(isinstance)
3 0.000 0.000 0.000 0.000 :0(len)
2 0.000 0.000 0.000 0.000 :0(print)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.156 0.156 <string>:1(<module>)
4 0.000 0.000 0.000 0.000 iostream.py:206(schedule)
3 0.000 0.000 0.000 0.000 iostream.py:418(_is_master_process)
3 0.000 0.000 0.000 0.000 iostream.py:437(_schedule_flush)
3 0.000 0.000 0.000 0.000 iostream.py:500(write)
4 0.000 0.000 0.000 0.000 iostream.py:96(_event_pipe)
1 0.000 0.000 0.156 0.156 profile:0(print(fib_seq(n)); print())
0 0.000 0.000 profile:0(profiler)
4 0.000 0.000 0.000 0.000 socket.py:543(send)
4 0.000 0.000 0.000 0.000 threading.py:1066(_wait_for_tstate_lock)
4 0.000 0.000 0.000 0.000 threading.py:1133(is_alive)
4 0.000 0.000 0.000 0.000 threading.py:536(is_set)
1 2 3 4 5 6 7 8 9 10 import timeitt = timeit.Timer("print('main statement')" , "print('setup')" ) print ('TIMEIT:' )print (t.timeit(2 ))print ('REPEAT:' )print (t.repeat(3 , 2 ))
TIMEIT:
setup
main statement
main statement
1.2299999980314169e-05
REPEAT:
setup
main statement
main statement
setup
main statement
main statement
setup
main statement
main statement
[0.00017259999958696426, 2.790000007735216e-05, 1.540000039312872e-05]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import contextlibimport timeclass Profile (contextlib.ContextDecorator): def __init__ (self, t=0.0 ): self.t = t def __enter__ (self ): self.start = self.time() return self def __exit__ (self, type , value, traceback ): self.dt = self.time() - self.start self.t += self.dt def time (self ): return time.time() ttt=Profile() with ttt: [_ for _ in range (int (1e7 ))] print (ttt.t)
0.534808874130249
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import sysprint ('Version info:' )print ()print ('sys.version =' , repr (sys.version))print ('sys.version_info =' , sys.version_info)print ('sys.hexversion =' , hex (sys.hexversion))print ('sys.api_version =' , sys.api_version)print ('This interpreter was built for:' , sys.platform)print ('Arguments:' , sys.argv)print ('Name:' , sys.implementation.name)print ('Version:' , sys.implementation.version)print ('Cache tag:' , sys.implementation.cache_tag)one = [] print ('At start :' , sys.getrefcount(one))two = one print ('Second reference :' , sys.getrefcount(one))del twoprint ('After del :' , sys.getrefcount(one))class MyClass : pass objects = [ [], (), {}, 'c' , 'string' , b'bytes' , 1 , 2.3 , MyClass, MyClass(), ] for obj in objects: print ('{:>10} : {}' .format (type (obj).__name__,sys.getsizeof(obj)))
Version info:
sys.version = '3.9.13 (main, Aug 25 2022, 23:51:50) [MSC v.1916 64 bit (AMD64)]'
sys.version_info = sys.version_info(major=3, minor=9, micro=13, releaselevel='final', serial=0)
sys.hexversion = 0x3090df0
sys.api_version = 1013
This interpreter was built for: win32
Arguments: ['C:\\Users\\Ada\\AppData\\Roaming\\Python\\Python39\\site-packages\\ipykernel_launcher.py', '--ip=127.0.0.1', '--stdin=9008', '--control=9006', '--hb=9005', '--Session.signature_scheme="hmac-sha256"', '--Session.key=b"fb322aac-cfd4-4a49-87ab-e11c0e6aea3e"', '--shell=9007', '--transport="tcp"', '--iopub=9009', '--f=c:\\Users\\Ada\\AppData\\Roaming\\jupyter\\runtime\\kernel-v2-100766YwHlokYHZ1d.json']
Name: cpython
Version: sys.version_info(major=3, minor=9, micro=13, releaselevel='final', serial=0)
Cache tag: cpython-39
At start : 2
Second reference : 3
After del : 2
list : 56
tuple : 40
dict : 64
str : 50
str : 55
bytes : 38
int : 28
float : 24
type : 1064
MyClass : 48
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class WithAttributes : def __init__ (self ): self.a = 'a' self.b = 'b' return def __sizeof__ (self ): return object .__sizeof__(self) + \ sum (sys.getsizeof(v) for v in self.__dict__.values()) my_inst = WithAttributes() print (sys.getsizeof(my_inst))print ('maxsize :' , sys.maxsize)print ('maxunicode:' , sys.maxunicode)
148
maxsize : 9223372036854775807
maxunicode: 1114111
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def my_excepthook (type , value, traceback print ('Unhandled error:' , type , value) sys.excepthook = my_excepthook print ('Before exception' )raise RuntimeError('This is the error message' )print ('After exception' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import sysimport threadingimport timedef do_something_with_exception (): exc_type, exc_value = sys.exc_info()[:2 ] print ('Handling {} exception with message "{}" in {}' .format ( exc_type.__name__, exc_value, threading.current_thread().name)) def cause_exception (delay ): time.sleep(delay) raise RuntimeError('This is the error message' ) def thread_target (delay ): try : cause_exception(delay) except RuntimeError: do_something_with_exception() threads = [ threading.Thread(target=thread_target, args=(0.3 ,)), threading.Thread(target=thread_target, args=(0.1 ,)), ] for t in threads: t.start() for t in threads: t.join()
Handling RuntimeError exception with message "This is the error message" in Thread-7
Handling RuntimeError exception with message "This is the error message" in Thread-6
1 2 3 4 5 6 7 8 9 10 import sysnames = sorted (sys.modules.keys()) name_text = ', ' .join(names) for d in sys.path: print (d)
d:\BaiduSyncdisk\Blog\source\_posts
e:\Anaconda3\envs\AAA\python39.zip
e:\Anaconda3\envs\AAA\DLLs
e:\Anaconda3\envs\AAA\lib
e:\Anaconda3\envs\AAA
C:\Users\Ada\AppData\Roaming\Python\Python39\site-packages
e:\Anaconda3\envs\AAA\lib\site-packages
e:\Anaconda3\envs\AAA\lib\site-packages\openea-1.0-py3.9.egg
e:\Anaconda3\envs\AAA\lib\site-packages\python_levenshtein-0.20.7-py3.9.egg
e:\Anaconda3\envs\AAA\lib\site-packages\gensim-4.2.0-py3.9-win-amd64.egg
e:\Anaconda3\envs\AAA\lib\site-packages\matching-0.1.1-py3.9.egg
e:\Anaconda3\envs\AAA\lib\site-packages\win32
e:\Anaconda3\envs\AAA\lib\site-packages\win32\lib
e:\Anaconda3\envs\AAA\lib\site-packages\Pythonwin
C:\Users\Ada\AppData\Roaming\Python\Python39\site-packages\IPython\extensions
C:\Users\Ada\.ipython
1 2 3 4 5 6 7 8 import osimport syssys.path.append(r'D:\BaiduSyncdisk\Blog\source' ) root='D:\BaiduSyncdisk\Blog\source' for dir_name, sub_dirs, files in os.walk(root): print (dir_name,sub_dirs,files)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for entry in os.scandir(root): if entry.is_dir(): typ = 'dir' elif entry.is_file(): typ = 'file' elif entry.is_symlink(): typ = 'link' else : typ = 'unknown' print ('{name} {typ}' .format ( name=entry.name, typ=typ, ))
1 2 3 4 5 6 7 8 9 print (os.getcwd())os.chdir('d:\\BaiduSyncdisk\\Blog\\source' ) print (os.getcwd())print (os.system('pwd' ))
d:\BaiduSyncdisk\Blog\source
d:\BaiduSyncdisk\Blog\source
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import platformprint ('uname:' , platform.uname())print ()print ('system :' , platform.system())print ('node :' , platform.node())print ('release :' , platform.release())print ('version :' , platform.version())print ('machine :' , platform.machine())print ('processor:' , platform.processor())print ('interpreter:' , platform.architecture())print ('/bin/ls :' , platform.architecture('/bin/ls' ))print ('Normal :' , platform.platform())print ('Aliased:' , platform.platform(aliased=True ))print ('Terse :' , platform.platform(terse=True ))print ('Version :' , platform.python_version())print ('Version tuple:' , platform.python_version_tuple())print ('Compiler :' , platform.python_compiler())print ('Build :' , platform.python_build())
uname: uname_result(system='Windows', node='DESKTOP-SFFEKV7', release='10', version='10.0.19041', machine='AMD64')
system : Windows
node : DESKTOP-SFFEKV7
release : 10
version : 10.0.19041
machine : AMD64
processor: Intel64 Family 6 Model 158 Stepping 10, GenuineIntel
interpreter: ('64bit', 'WindowsPE')
/bin/ls : ('64bit', '')
Normal : Windows-10-10.0.19041-SP0
Aliased: Windows-10-10.0.19041-SP0
Terse : Windows-10
Version : 3.9.13
Version tuple: ('3', '9', '13')
Compiler : MSC v.1916 64 bit (AMD64)
Build : ('main', 'Aug 25 2022 23:51:50')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import resourceRESOURCES = [ ('ru_utime' , 'User time' ), ('ru_stime' , 'System time' ), ('ru_maxrss' , 'Max. Resident Set Size' ), ('ru_ixrss' , 'Shared Memory Size' ), ('ru_idrss' , 'Unshared Memory Size' ), ('ru_isrss' , 'Stack Size' ), ('ru_inblock' , 'Block inputs' ), ('ru_oublock' , 'Block outputs' ), ] usage = resource.getrusage(resource.RUSAGE_SELF) for name, desc in RESOURCES: print ('{:<25} ({:<10}) = {}' .format ( desc, name, getattr (usage, name)))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import gc''' enable() --启用自动垃圾回收。 disable() --禁用自动垃圾回收。 isenabled() --如果启用了自动收集,则返回true。 collect() --立即执行完全收集。 get_count() --返回当前集合计数。 get_stats() --返回包含每代统计信息的词典列表。 set_debug() --设置调试标志。 get_debug() --获取调试标志。 set_threshold() --设置收集阈值。 get_threshold() --返回集合阈值的当前值。 get_objects() --返回收集器跟踪的所有对象的列表。 is_tracked() --如果跟踪给定对象,则返回true。 is_finalized() --如果给定对象已定稿,则返回true。 get_referrers() --返回引用对象的对象列表。 get_referents() --返回对象引用的对象列表。 freeze() --冻结所有跟踪对象,并在将来的收集中忽略它们。 unfreeze() --解冻永久生成中的所有对象。 get_freeze_count() --返回永久生成中的对象数。 ''' import sysclass Test (): def __init__ (self ): pass t = Test() k = Test() t._self = t print (sys.getrefcount(t)) print (sys.getrefcount(k))
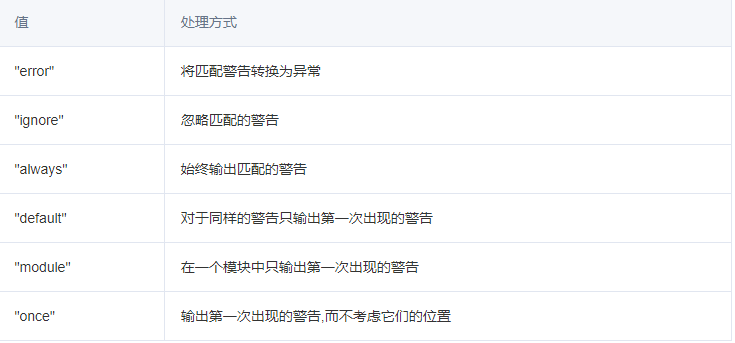
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import warningswarnings.simplefilter('ignore' , UserWarning) print ('Before the warning' )warnings.warn('This is a warning message' ) print ('After the warning' )warnings.filterwarnings('ignore' , '.*do not.*' ,) warnings.warn('Show this message' ) warnings.warn('Do not show this message' )
Before the warning
After the warning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import warningswarnings.simplefilter('once' , UserWarning) def warning_on_one_line (message, category, filename, lineno, file=None , line=None ): return '-> {}:{}: {}:{}\n' .format ( filename, lineno, category.__name__, message) warnings.warn('Warning message, before' ) warnings.formatwarning = warning_on_one_line warnings.warn('Warning message, after' ) warnings.warn('This is a warning!' ) warnings.warn('This is a warning!' ) warnings.warn('This is a warning!' )
C:\Users\Ada\AppData\Local\Temp/ipykernel_9460/3571311107.py:9: UserWarning: Warning message, before
warnings.warn('Warning message, before')
-> C:\Users\Ada\AppData\Local\Temp/ipykernel_9460/3571311107.py:11: UserWarning:Warning message, after
-> C:\Users\Ada\AppData\Local\Temp/ipykernel_9460/3571311107.py:13: UserWarning:This is a warning!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import disdef f (*args ): nargs = len (args) print (nargs, args) if __name__ == '__main__' : import dis dis.dis(f) dis.show_code(f)
6 0 LOAD_GLOBAL 0 (len)
2 LOAD_FAST 0 (args)
4 CALL_FUNCTION 1
6 STORE_FAST 1 (nargs)
7 8 LOAD_GLOBAL 1 (print)
10 LOAD_FAST 1 (nargs)
12 LOAD_FAST 0 (args)
14 CALL_FUNCTION 2
16 POP_TOP
18 LOAD_CONST 0 (None)
20 RETURN_VALUE
Name: f
Filename: C:\Users\Ada\AppData\Local\Temp/ipykernel_9460/3862671634.py
Argument count: 0
Positional-only arguments: 0
Kw-only arguments: 0
Number of locals: 2
Stack size: 3
Flags: OPTIMIZED, NEWLOCALS, VARARGS, NOFREE
Constants:
0: None
Names:
0: len
1: print
Variable names:
0: args
1: nargs
1 2 3 4 5 6 7 8 9 10 11 12 13 import inspectimport examplefor name, data in inspect.getmembers(example): if name.startswith('__' ): continue print ('{} : {!r}' .format (name, data))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import importlib''' ├── clazz │ ├── __init__.py │ ├── a.py │ └── b.py └── main.py a.py def show(): print("show A") b.py def show(): print("show B") ''' import osimport importlibdef get_modules (package="." ): """ 获取包名下所有非__init__的模块名 """ modules = [] files = os.listdir(package) for file in files: if not file.startswith("__" ): name, ext = os.path.splitext(file) modules.append("." + name) return modules if __name__ == '__main__' : package = "clazz" modules = get_modules(package) for module in modules: module = importlib.import_module(module, package) for attr in dir (module): if not attr.startswith("__" ): func = getattr (module, attr) func() """ show A show B """
1 2 3 4 5 6 7 8 9 10 11 12 13 import pkgutiliter_modules(path=None , prefix='' ) walk_packages(path=None , prefix='' , onerror=None ) for _, name, ispkg in pkgutil.walk_packages(test.__path__, test.__name__ + "." ): print "name: {0:12}, is_sub_package: {1}" .format (name, ispkg)